
By Phodal(Follow me: 微博、知乎、SegmentFault)
阅读过程中遇到任何问题,请以issue的形式提出来,这样可以帮助其他读者来发现这个问题。
GitHub: 全栈增长工程师实战
PDF、Mobi、Epub版本下载地址:https://github.com/phodal/growth-in-action/releases
微信公众号
我的其他电子书:
黄峰达(Phodal Huang)是一个创客、工程师、咨询师和作家。他毕业于西安文理学院电子信息工程专业,现作为一个咨询师就职于 ThoughtWorks 深圳。长期活跃于开源软件社区 GitHub,目前专注于物联网和前端领域。
作为一个开源软件作者,著有 Growth、Stepping、Lan、Echoesworks 等软件。其中开源学习应用 Growth,广受读者和用户好评,可在 APP Store 及各大 Android 应用商店下载。
作为一个技术作者,著有《自己动手设计物联网》(电子工业出版社)、《全栈应用开发:精益实践》(电子工业出版社,正在出版)。并在 GitHub 上开源有《Growth: 全栈增长工程师指南》、《GitHub 漫游指南》等七本电子书。
作为技术专家,他为英国 Packt 出版社审阅有物联网书籍《Learning IoT》、《Smart IoT》,前端书籍《Angular 2 Serices》、《Getting started with Angular》等技术书籍。
他热爱编程、写作、设计、旅行、hacking,你可以从他的个人网站:https://www.phodal.com/ 了解到更多的内容。
其它相关信息:
当前为预览版,在使用的过程中遇到任何问题请及时与我联系。阅读过程中的问题,不妨在GitHub上提出来: Issues
阅读过程中遇到语法错误、拼写错误、技术错误等等,不妨来个Pull Request,这样可以帮助到其他阅读这本电子书的童鞋。
我的电子书:
我的微信公众号:

支持作者,可以加入作者的小密圈:

或者转账:


记得我们在《RePractise前端篇: 前端演进史》中提到技术在最近十几年的飞速发展,当然最主要的就是:技术的复杂度不断地从应用层抽象到了框架层。虽说:
技术的复杂度同力一样不会消失,也不会凭空产生,它总是从一个物体转移到另一个物体或一种形式转为另一种形式。
然而这也意味着成为一个全栈工程师,比以往的任何一个时间要容易得多。这也意味着一个全栈工程师也可以很快地成为一个Growth Hacking(中文:增长黑客)。所以,我们开始谈论如何成为一名全栈增长工程师。
在电子书《全栈增长工程师指南》中,我们提到过成为全栈增长工程师的技术基础,但是没有并没有谈论到如何成为这样的全栈工程师——这是一个漫长的过程。
早期,当我们有一个想法的时候,我们会去搭建一个网站——如以WordPress作为CMS,以RoR、Django来开发应用等等。随后,我们将我们的网站推向市场,发现市场有点反应。
接着,我们不断地开发出一些新的功能——如CMS的留言、Sitemap等等。在这个过程中,我们会开发一些API来满足我们的需求。
在一个新的阶段里,我们开始推出移动应用。基于先前的API,我们不断地构建出了不同的API。或以单体应用的形式出现,或以微服务的形式产生出新的API。
然后,我们发现并不是所有的移动用户都愿意去下载我们的API。于是,我们推出了SPA(单页面应用),以此来迎接那些移动设备用户。
最后,我们的业务逐渐稳定了下来。我们开始了一些优化工作,或者如Facebook一样优化PHP,推出HHVM。或者如Netflix一样使用微服务解耦系统。又或者,我们使用新的架构对我们的系统进行重新的设计。
在整个过程中,我们将学习到如何去做网站后台、移动应用、API设计、前端单页面应用等等。从这种意义上来说,全栈工程师非常match初创企业所需要的技术要求。
Growth整一个系列:APP、社区、电子书《全栈增长工程师指南》、电子书《全栈增长工程师实战》算是我对Growth Hacking的一个研究。不过,对于一个人来说这工作量还是蛮大的——在完成两本电子书后,我们将继续研究。在这一个过程中,我发现一些很有意思的东西——只有开发出用户想要的东西,这个过程才容易实践起来的。
增长可以分为两部分:一个是自身的增长,一个是用户的增长。两者实际上是一种相互促进的关系,当我们的能力增长到一定的程度,我们才能推进用户的增长。相用户增长到一定的程度,也会推进我们的技能增长。
只是要在技术、数据分析、用户分析、创新等等有所突破,看上去好像不是一件容易的事。只是对于大部分的全栈工程师来说,实现技术、数据抓取和分析是一件容易的事。要实现对数据的敏感是一种很难的事,但是可视化过后的数据就一样了。对于用户的行为分析也是类似的,只是因为我们缺乏一些有效的练习。
更让人惊讶的是创新也是可以练习的,每次我们遇到一个问题的时候,就是我们离创新最近的时候——难道不是吗?当你遇到一个难解的问题,就是你开拓一个新的能力的时候。
好好享受这个学习的过程吧!
在开始写代码之前你需要保证你有一些Python基础,如果没有的话,请参阅其他相关书籍来一起学习。
并且你还需要在你的计算机上安装:
Django是一个高级的Python Web开发框架,它的目标是使得开发复杂的、数据库驱动的网站变得更加简单。
由于Django最初是被开发来用于管理劳伦斯出版集团旗下的一些以新闻内容为主的网站的。所以,我们可以发现在使用Django的很多网站里,都是用于作为CMS(内容管理系统)来使用的。使用Django的一些比较知名的网站如下图所示:

Django是一个MTV框架,其架构模板看上去与传统的MVC架构并没有太大的区别。其对比如下表所示:
| 传统的MVC架构 | Django 架构 |
|---|---|
| Model | Model(Data Access Logic) |
| View | Template(Presentation Logic) |
| View | View(Business Logic) |
| Controller | Django itself |
在Django中View只用来描述你要看到的内容,Template才是最后用于显示的内容。而在MVC架构中,这只相当于是View层。它的核心包含下面的四部分:
其核心框架还包含:
Django的每一个模块在内部都称之为APP,在每个APP里都有自己的三层结构。如下图所示:
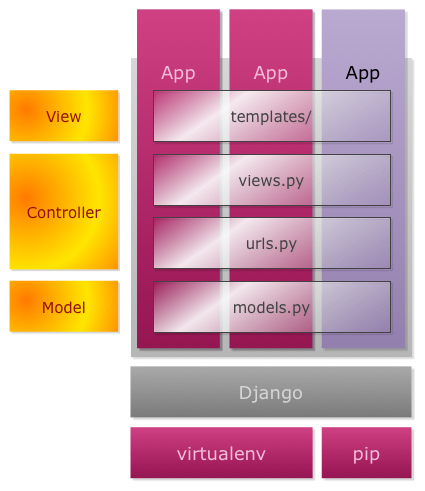
这样做不仅可以在开发的时候更容易理解系统,而且可以提高代码的可复用性——因为每一个APP都是独立的应用,在下次使用时我们只需要简单的复制和粘贴。
说了这么多,还不如从一个hello,world开始。
安装Django之前,我们可以用virtualenv工具来创建一个虚拟的Python运行环境。环境问题是一个很复杂的问题,在我们使用Python的过程中,我们会不断地安装一些库,而这些库可能会有不同的版本。并且在安装Python库的过程中,我们会遇到权限问题——即我们需要超级用户的权限才能将库安装到系统的环境之下。随后在这个软件的生涯中,我们还需要保证这个项目所依赖的模块不会发生变动。而这些都是很棘手的一些事,这时候我们就需要创建一个虚拟的运行环境,而virtualenv就是这样的一个工具。
安装Python包我们需要用到pip命令,它是Python语言中的一个包管理工具。如果你没有安装的话,可以使用下面的命令来安装:
curl https://bootstrap.pypa.io/get-pip.py | python在不同的Python环境中,我们可能需要使用不同的pip,如下所示是笔者使用的Python3的pip命令pip3
$ pip3 install virtualenv如果是Python2.7的话,对应会有:
$ pip install virtualenv需要注意的是这将会安装到Python所在的目录,如我的目录是:
$ /usr/local/bin/virtualenv有的可能会是:
$ /usr/local/share/python3/virtualenv在创建我们的这个虚拟环境之前,我们可以创建一个存储所有virtualenv的目录:
$ mkdir somewhere/virtualenvs现在,我们就可以创建一个新的虚拟环境:
$ virtualenv somewhere/virtualenvs/<project-name> --no-site-packages如果你想使用不同的Python版本的话,那么需要指定Python版本的路径
$ virtualenv --distribute -p /usr/local/bin/python3.3 somewhere/virtualenvs/<project-name>通过到相应的目录下执行激活就可以使用这个虚拟环境了:
$ cd somewhere/virtualenvs/<project-name>/bin
$ source activate停止使用只需要执行下面的命令即可:
$ deactivate准备了这么久我们终于要开始安装Django了,执行:
$ pip install django开始下最新版本的Django,如下所示:
Collecting django
Downloading Django-1.9.4-py2.py3-none-any.whl (6.6MB)
94% |██████████████████████████████▎ | 6.2MB 251kB/s eta 0:00:02等下载完后,就会开始安装Django。安装完后,我们就可以使用Django自带的django-admin命令。django-admin是Django自带的一个管理任务的命令行工具。
通过这个命令,我们不仅仅可以用它来创建项目、创建app、运行服务、数据库迁移,还可以执行各种SQL工具等等。django-admin用法如下:
$ django-admin <command> [options]下面是django-admin自带的一些命令:
[django]
check
compilemessages
createcachetable
dbshell
diffsettings
dumpdata
flush
inspectdb
loaddata
makemessages
makemigrations
migrate
runfcgi
runserver
shell
sql
sqlall
sqlclear
sqlcustom
sqldropindexes
sqlflush
sqlindexes
sqlinitialdata
sqlmigrate
sqlsequencereset
squashmigrations
startapp
startproject
syncdb
test
testserver
validate现在,让我们来看看这个强大的工具。
在这些命令中startproject可以用于创建项目,在这里我们的项目名是blog,那么我们的命令如下:
$ django-admin startproject blog
这个命令将创建下面的文件内容,而这些是Django项目的一些必须文件。
.
├── blog
│ ├── __init__.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
└── manage.pyblog目录对应的就是blog这个项目,将会放置这个项目的一些相关配置:
manage.py 会在每个Django项目中自动生成,它可以和django-admin做类似的事。如我们可以用manage.py来启动测试环境的服务器:
$ python manage.py runserver
Performing system checks...
System check identified no issues (0 silenced).
You have unapplied migrations; your app may not work properly until they are applied.
Run 'python manage.py migrate' to apply them.
March 24, 2016 - 03:07:34
Django version 1.9.4, using settings 'blog.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.
Not Found: /
[24/Mar/2016 03:07:35] "GET / HTTP/1.1" 200 1767
Not Found: /favicon.ico
[24/Mar/2016 03:07:36] "GET /favicon.ico HTTP/1.1" 404 1934现在,我们只需要在浏览器中打开http://127.0.0.1:8000/,便可以访问我们的应用程序。
Django很适合CMS的另外一个原因,就是它自带了一个后台管理系统。为了启用这个后台管理系统,我们需要配置我们的数据库,并创建相应的超级用户。如下所示的是settings.py中的默认数据库配置:
# Database
# https://docs.djangoproject.com/en/1.7/ref/settings/#databases
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
}
}上面的配置中我们使用的是SQLite3作为数据库,并使用了当前目录下的db.sqlite3作为数据库文件。Django内建支持下面的一些数据库:
'django.db.backends.postgresql_psycopg2'
'django.db.backends.mysql'
'django.db.backends.sqlite3'
'django.db.backends.oracle'如果我们想使用别的数据库,可以在网上寻找相应的解决方案,如用于支持使用MongoDB的django-nonrel项目。不同的数据库有不同的配置,如下所示的是使用PostgreSQL的配置。
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': 'mydatabase',
'USER': 'mydatabaseuser',
'PASSWORD': 'mypassword',
'HOST': '127.0.0.1',
'PORT': '5432',
}
}接着,我们就可以运行数据库迁移,只需要运行相应的脚本即可:
$ python manage.py migrate
Operations to perform:
Apply all migrations: sessions, admin, auth, contenttypes
Running migrations:
Rendering model states... DONE
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying sessions.0001_initial... OK
(growth-django)在上面的过程中,我们会创建相应的数据库模型,并依据迁移脚本来创建一些相应的数据,如默认的配置等等。
最后,我们可以创建一个相应的超级用户来登陆后台。
$ python manage.py createsuperuser
Username (leave blank to use 'fdhuang'): root
Email address: h@phodal.com
Password:
Password (again):
Superuser created successfully.输入相应的用户名和密码,即可完成创建。然后访问 http://127.0.0.1:8000/admin,输入上面的用户名和密码就可以来到后台:
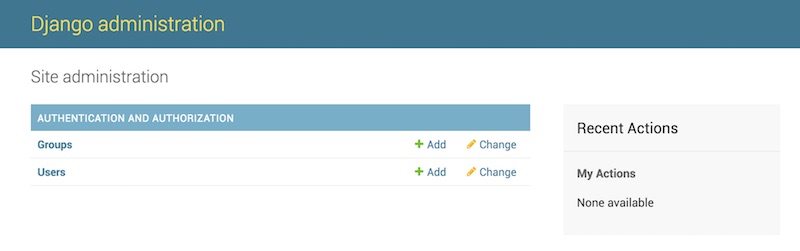
在创建完应用后,我们就可以进行第一次提交,通常初次提交的提交信息(commit message)是init project。如果在那之前,你没有执行git init来初始化git的话,那么我们就需要去执行这个命令。
git init它将返回类似于下面的结果
Initialized empty Git repository in /Users/fdhuang/test/helloworld/.git/即初始化了一个空的Git项目,然后我们就可以执行add来添加上面的内容:
git add .需要注意的是上面的数据库文件不应该添加到项目里,所以我们应该执行reset命令来重置这个状态:
git reset db.sqlite3这时我们会将其变成下面的状态:
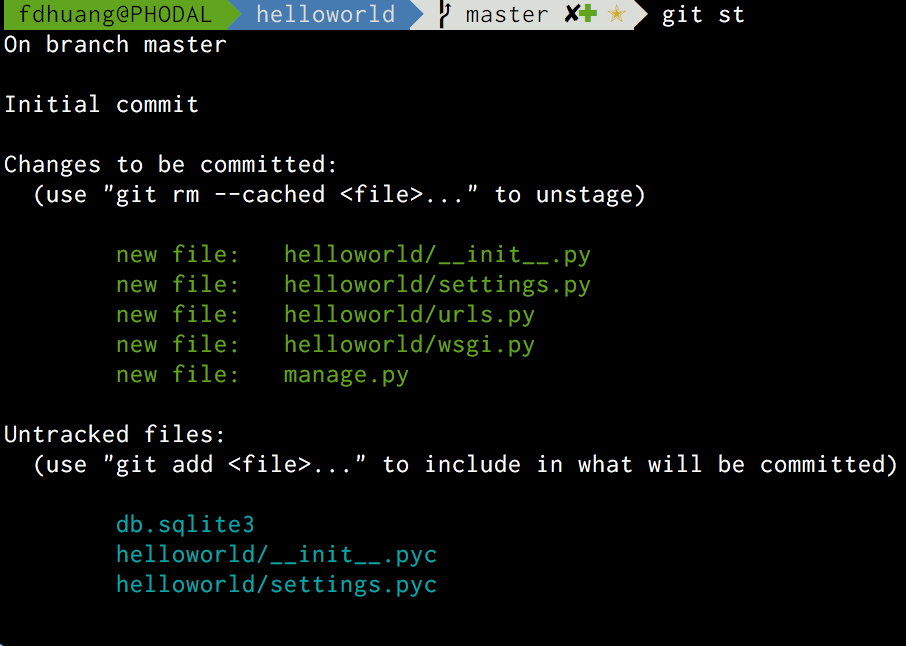
上面的绿色文件代表这几个文件都被添加了进去,蓝色则代表未添加的文件。为了避免手误产生一些问题,我们需要添加一个名为.gitignore文件用于将一些文件名加入忽略名单,如下是常用的python项目的.gitignore文件中的内容:
*.pyc
*.db
*.sqlite3当我们添加完这个文件,git就会识别这个文件,并忽略原来的那些文件,如下图所示:
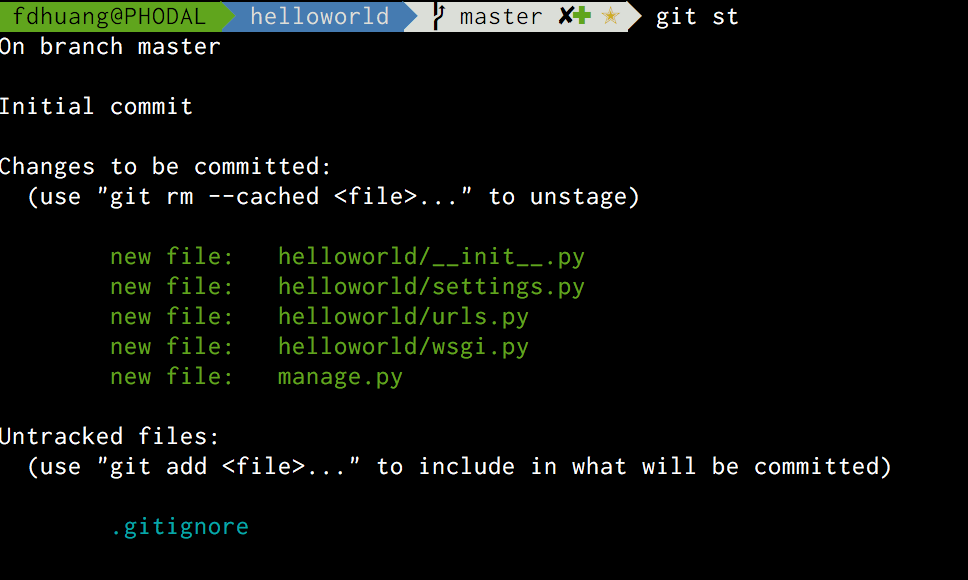
我们只需要添加这个文件即可:
git add .gitignore如果你之前已经不小心添加了一些不应该添加的文件,那么可以执行下面的命令来重置其状态:
git reset .然后再执行添加命令。
最后,我们就可以在本地提交我们的代码了:
git commit -m "init project"如果你是将代码托管在GitHub上的话,那么你就可以执行git push来将代码提交到服务器上。
在我们不了解Django的时候,要对这样一个任务进行Tasking,有点困难。不过,我们还是可以简单地看看是应该如何去做:
对于其他应用来说也是差不多的。
现在我们可以开始创建我们的APP,使用下面的代码来创建:
$ django-admin startapp blogpost
会在blogpost目录下,生成下面的文件:
.
├── __init__.py
├── admin.py
├── apps.py
├── migrations
│ └── __init__.py
├── models.py
├── tests.py
└── views.py现在,我们需要来创建博客的Model即可。对于一篇基本的博客来说,它会包含下面的几部分内容:
我们就可以按照上面的内容来创建我们的Blogpost model:
from django.db import models
from django.db.models import permalink
class Blogpost(models.Model):
title = models.CharField(max_length=100, unique=True)
author = models.CharField(max_length=100, unique=True)
slug = models.SlugField(max_length=100, unique=True)
body = models.TextField()
posted = models.DateField(db_index=True, auto_now_add=True)
def __unicode__(self):
return '%s' % self.title
@permalink
def get_absolute_url(self):
return ('view_blog_post', None, { 'slug': self.slug })上面的get_absolute_url方法就是用于返回博客的链接。之所以使用手动而不是自动生成,是因为自动生成不靠谱,而且不利
然后在Admin注册这个Model
from django.contrib import admin
from blogpost.models import Blogpost
class BlogpostAdmin(admin.ModelAdmin):
exclude = ['posted']
prepopulated_fields = {'slug': ('title',)}
admin.site.register(Blogpost, BlogpostAdmin)接着我们需要先将blogpost这个APP添加到配置文件blog/blog/settings.py的INSTALLED_APPS字段中:
INSTALLED_APPS = [
'blogpost.apps.BlogpostConfig',
'django.contrib.admin',
...
]然后做数据库迁移:
python manage.py migrate这时会提示:
Operations to perform:
Apply all migrations: admin, contenttypes, auth, sessions
Running migrations:
No migrations to apply.
Your models have changes that are not yet reflected in a migration, and so won't be applied.
Run 'manage.py makemigrations' to make new migrations, and then re-run 'manage.py migrate' to apply them.是因为我们忘记了先运行
python manage.py makemigrations进入后台,我们就可以看到BLOGPOST的一栏里,就可以对其进行相关的操作。
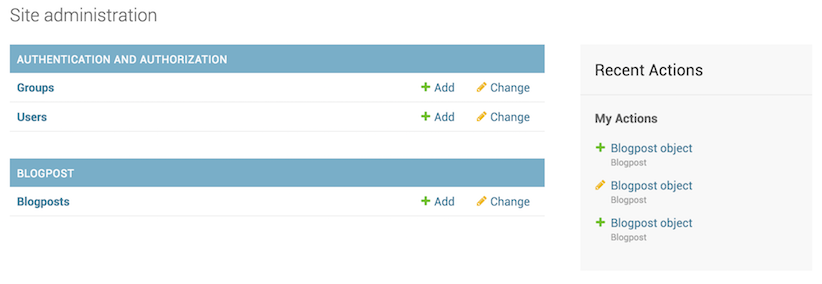
点击Blogpost的Add后,我们就会进入如下的添加博客界面:
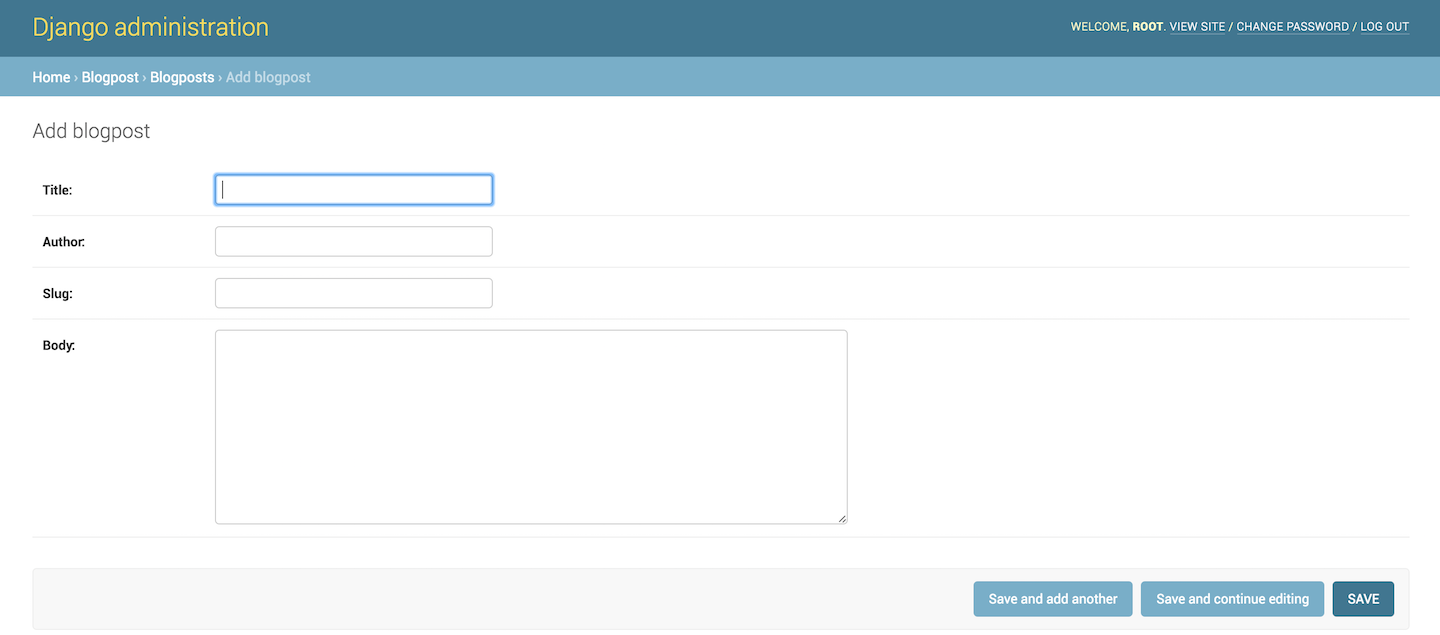
实际上,这样做的意义是将删除(Delete)、修改(Update)、添加(Create)这些内容交给用户后台来做,当然它也不需要在View/Template层来做。在我们的Template层中,我们只需要关心如何来显示这些数据。
现在,我们可以执行一次新的代码提交——因为现在的代码可以正常工作。这样出现问题时,我们就可以即时的返回上一版本的代码。
git add .
git commit -m "create blogpost model"然后再进行下一步地操作。
现在,我们就可以在我们的urls.py里添加相应的route来访问页面,代码如下所示:
from django.conf import settings
from django.conf.urls import include, url
from django.conf.urls.static import static
from django.contrib import admin
urlpatterns = [
(r'^$', 'blogpost.views.index'),
url(r'^blog/(?P<slug>[^\.]+).html', 'blogpost.views.view_post', name='view_blog_post'),
url(r'^admin/', include(admin.site.urls))
]在上面的代码里,我们创建了两个route:
指向博客详情页的URL正则r'^blog/(?P<slug>[^\.]+).html,会将形如blog/hello-world.html中的hello-world提取出来作为参数传给view_post方法。
接着,我们就可以创建两个view。
对于我们的首页来说,我们可以简单的只显示五篇博客,所以我们所需要做的就是从我们的Blogpost对象中,取出前五个结果即可。代码如下所示:
from django.shortcuts import render, render_to_response, get_object_or_404
from blogpost.models import Blogpost
def index(request):
return render_to_response('index.html', {
'posts': Blogpost.objects.all()[:5]
})Django的render_to_response方法可以根据一个给定的上下文字典渲染一个给定的目标,并返回渲染后的HttpResponse。即将相应的值,如这里的Blogpost.objects.all()[:5],填入相应的index.html中,再返回最后的结果。
首先,我们需要创建一个templates文件夹,然后在setting.py的TEMPLATES字段将该目录指定为默认目录
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': ['templates/'],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]另外,在templates目录下我们需要新建base.html, index.html和blogpost_detail.html三个模板。
{% load staticfiles %}
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>{% block head_title %}Welcome to my blog{% endblock %}</title>
<link rel="stylesheet" type="text/css" href="{% static 'css/bootstrap.min.css' %}">
<link rel="stylesheet" type="text/css" href="{% static 'css/styles.css' %}">
</head>
<body data-twttr-rendered="true" class="bs-docs-home">
<header class="navbar navbar-static-top bs-docs-nav" id="top" role="banner">
<div class="container">
<div class="navbar-header">
<button class="navbar-toggle collapsed" type="button" data-toggle="collapse"
data-target=".bs-navbar-collapse">
<span class="sr-only">切换视图</span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
</button>
<a href="/" class="navbar-brand">Growth博客</a>
</div>
<nav class="collapse navbar-collapse bs-navbar-collapse" role="navigation">
<ul class="nav navbar-nav">
<li>
<a href="/pages/about/">关于我</a>
</li>
<li>
<a href="/pages/resume/">简历</a>
</li>
</ul>
<ul class="nav navbar-nav navbar-right">
<li><a href="/admin" id="loginLink">登入</a></li>
</ul>
<div class="col-sm-3 col-md-3 pull-right">
<form class="navbar-form" role="search">
<div class="input-group">
<input type="text" id="typeahead-input" class="form-control" placeholder="Search" name="search" data-provide="typeahead">
<div class="input-group-btn">
<button class="btn btn-default search-button" type="submit"><i class="glyphicon glyphicon-search"></i></button>
</div>
</div>
</form>
</div>
</nav>
</div>
</header>
<main class="bs-docs-masthead" id="content" role="main">
<div class="container">
<div id="carbonads-container">
THE ONLY FAIR IS NOT FAIR <br>
ENJOY CREATE & SHARE
</div>
</div>
</main>
<div class="container" id="container">
{% block content %}
{% endblock %}
</div>
<footer class="footer">
<div class="container">
<p class="text-muted">@Copyright Phodal.com</p>
</div>
</footer>
<script src="{% static 'js/jquery.min.js' %}"></script>
<script src="{% static 'js/bootstrap.min.js' %}"></script>
<script src="{% static 'js/bootstrap3-typeahead.min.js' %}"></script>
<script src="{% static 'js/main.js' %}"></script>
</body>
</html>在我们的index.html中,我们就可以拿到前五篇博客。我们只需要遍历出posts,拿出每个post相应的值,就可以完成列表页。
{% extends 'base.html' %}
{% block title %}Welcome to my blog{% endblock %}
{% block content %}
<h1>Posts</h1>
{% for post in posts %}
<h2><a href="{{ post.get_absolute_url }}">{{ post.title }}</a></h2>
<p>{{post.posted}} - By {{post.author}}</p>
<p>{{post.body}}</p>
{% endfor %}
{% endblock %}在上面的模板里,我们还取出了博客的链接用于跳转到详情页。
依据上面拿到的slug,我们就可以创建对应的详情页的view,代码如下所示:
def view_post(request, slug):
return render_to_response('blogpost_detail.html', {
'post': get_object_or_404(Blogpost, slug=slug)
})这里的get_object_or_404将会根据slug来获取相应的博客,如果取不出相应的博客就会返回404。因此,我们的详情页和上面的列表页也是类似的。
{% extends 'base.html' %}
{% block head_title %}{{ post.title }}{% endblock %}
{% block title %}{{ post.title }}{% endblock %}
{% block content %}
<h2>{{ post.title }}</a></h2>
<p>{{post.posted}} - By {{post.author}}</p>
<p>{{post.body}}</p>
{% endblock %}随后,我们就可以再提交一次代码了。
TDD虽然是一个非常好的实践,但是那是对于那些已经习惯写测试的人来说。如果你写测试的经历非常少,那么我们就可以从写测试开始。
在这里我们使用的是Django这个第三方框架来完成我们的工作,所以我们并不对这个框架的功能进行测试。虽然有些时候正是因为这些第三方框架的问题而导致的Bug,但是我们仅仅只是使用一些基础的功能。这些基础的功能也已经在他们的框架中测试过了。
先来做一个简单的测试,即测试我们访问首页的时候,调用的函数是上面的index函数
from django.core.urlresolvers import resolve
from django.http import HttpRequest
from django.test import TestCase
from blogpost.views import index, view_post
class HomePageTest(TestCase):
def test_root_url_resolves_to_home_page_view(self):
found = resolve('/')
self.assertEqual(found.func, index)但是这样的测试看上去没有多大意义,不过它可以保证我们的route可以和我们的URL对应上。在编写完测试后,我们就可以命令提示行中运行:
python manage.py test来查看测试的结果:
Creating test database for alias 'default'...
.
----------------------------------------------------------------------
Ran 1 test in 0.031s
OK
Destroying test database for alias 'default'...
(growth-django)运行通过,现在我们可以进行下一个测试了——我们可以测试页面的标题是不是我们想要的结果:
def test_home_page_returns_correct_html(self):
request = HttpRequest()
response = index(request)
self.assertIn(b'<title>Welcome to my blog</title>', response.content)这里我们需要去请求相应的页面来获取页面的标题,并用assertIn方法来断言返回的首页的html中含有<title>Welcome to my blog</title>。
同样的我们也可以用测试是否调用某个函数的方法,来看博客的详情页的route是否正确?
class BlogpostTest(TestCase):
def test_blogpost_url_resolves_to_blog_post_view(self):
found = resolve('/blog/this_is_a_test.html')
self.assertEqual(found.func, view_post)与上面测试首页不一样的是,在我们的Blogpost测试中,我们需要创建数据,以确保这个流程是没有问题的。因此我们需要用Blogpost.objects.create方法来创建一个数据,然后访问相应的页面来看是否正确。
def test_blogpost_create_with_view(self):
Blogpost.objects.create(title='hello', author='admin', slug='this_is_a_test', body='This is a blog',
posted=datetime.now)
response = self.client.get('/blog/this_is_a_test.html')
self.assertIn(b'This is a blog', response.content)或许你会疑惑这个数据会不会被注入到数据库中,请看运行测试时返回的结果的第一句:
Creating test database for alias 'default'...Django将会创建一个数据库用于测试。
同理,我们也可以为首页添加一个相似的测试:
def test_blogpost_create_with_show_in_homepage(self):
Blogpost.objects.create(title='hello', author='admin', slug='this_is_a_test', body='This is a blog',
posted=datetime.now)
response = self.client.get('/')
self.assertIn(b'This is a blog', response.content)我们用同样的方法创建了一篇博客,然后在首页测试返回的内容中是否含有This is a blog。
在上一章最后,我们写的测试可以算得上是单元测试,接着我们可以写一些自动化测试。
接着我们就可以用Selenium来做自动化测试。这是ThoughtWorks出品的一个强大的基于浏览器的开源自动化测试工具,它通常用来编写Web 应用的自动化测试。
先让我们来看一个自动化测试的例子:
from django.test import LiveServerTestCase
from selenium import webdriver
class HomepageTestCase(LiveServerTestCase):
def setUp(self):
self.selenium = webdriver.Firefox()
self.selenium.maximize_window()
super(HomepageTestCase, self).setUp()
def tearDown(self):
self.selenium.quit()
super(HomepageTestCase, self).tearDown()
def test_visit_homepage(self):
self.selenium.get(
'%s%s' % (self.live_server_url, "/")
)
self.assertIn("Welcome to my blog", self.selenium.title)在setUp——即开始的时候,我们会用selenium启动一个Firefox浏览器的进程,并执行maximize_window来将窗口最大化。在tearDown——即结束的时候,我们就会关闭这个浏览器的进程。我们的主要测试代码就在test_visit_homepage这个方法里,我们在里面访问首页,并判断标题是不是Welcome to my blog。
运行上面的测试就会启动一个浏览器,并且会在浏览器上进行相应的操作。如下图所示:
这时你可能会产生一些疑惑,这些内容我们不是已经测试过了么?两者从测试看是差不多的,但是从流程上看来说并不是如些。下图是页面渲染的时间线:
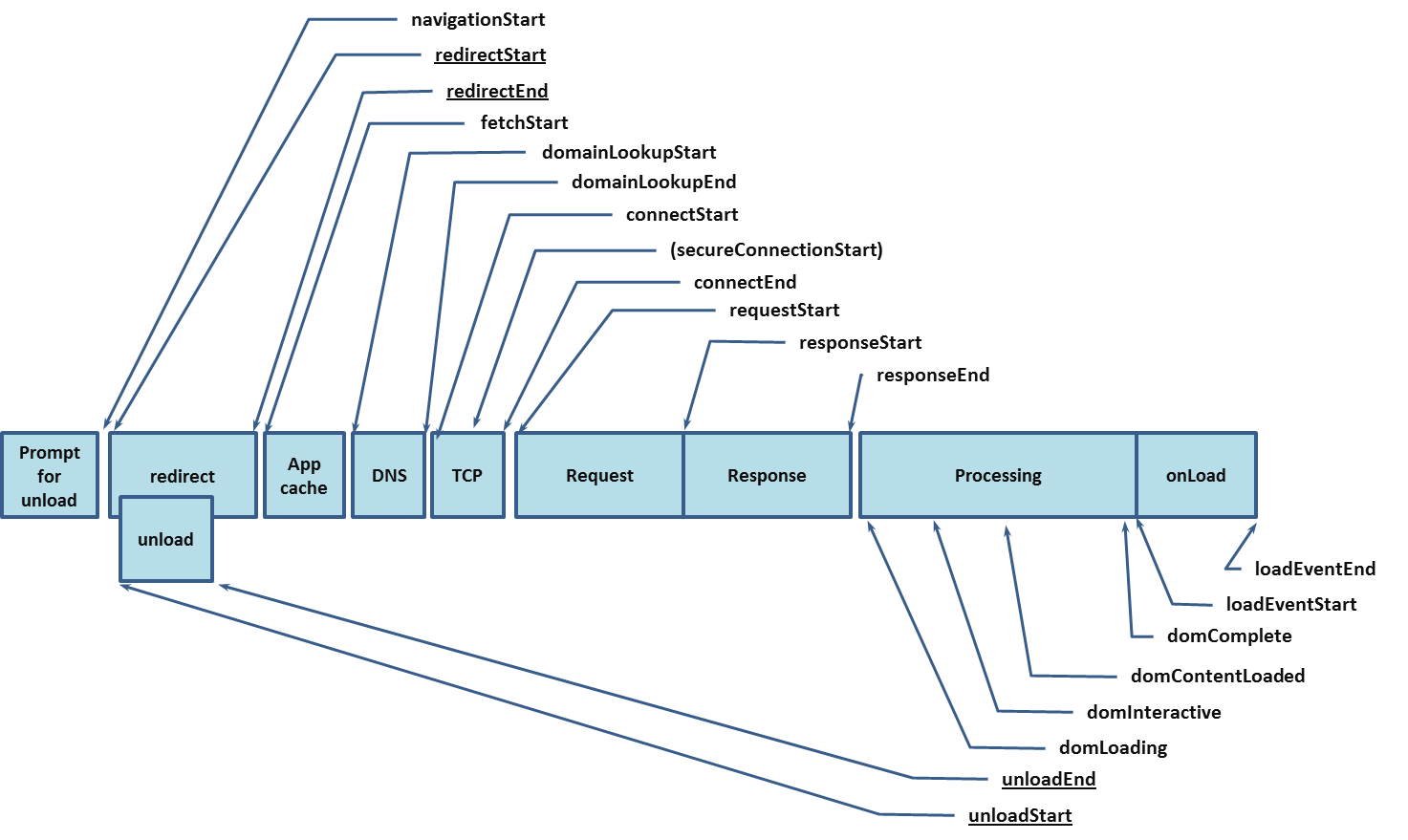
请求从浏览器传到服务器要有一系列的过程,如重定向、缓存、DNS等等,最后直至返回对应的Response。我们用Django的测试框架只能实现到这一步,随后页面请请求对应的静态资料,再对页面进行渲染,在这个过程中页面的内容会发生一些变化。
为了避免页面的内容被替换掉,那么我们就需要对这部分内容进行测试。
如下的代码也是可以用于测试页面内容的代码:
class BlogpostDetailCase(LiveServerTestCase):
def setUp(self):
Blogpost.objects.create(
title='hello',
author='admin',
slug='this_is_a_test',
body='This is a blog',
posted=datetime.now
)
self.selenium = webdriver.Firefox()
self.selenium.maximize_window()
super(BlogpostDetailCase, self).setUp()
def tearDown(self):
self.selenium.quit()
super(BlogpostDetailCase, self).tearDown()
def test_visit_blog_post(self):
self.selenium.get(
'%s%s' % (self.live_server_url, "/blog/this_is_a_test.html")
)
self.assertIn("hello", self.selenium.title)虽然在这里我们要测试的只是页面的标题,而实际上我们要测试的是页面的元素是否存在。
同样的,我们也可以对博客的内容进行测试。这些稍有不同的是,我们更多地是要测试用户的行为,如我们在首页点击某个链接,那么我应该中转到对应的博客详情页,如下代码所示:
class BlogpostFromHomepageCase(LiveServerTestCase):
def setUp(self):
Blogpost.objects.create(
title='hello',
author='admin',
slug='this_is_a_test',
body='This is a blog',
posted=datetime.now
)
self.selenium = webdriver.Firefox()
self.selenium.maximize_window()
super(BlogpostFromHomepageCase, self).setUp()
def tearDown(self):
self.selenium.quit()
super(BlogpostFromHomepageCase, self).tearDown()
def test_visit_blog_post(self):
self.selenium.get(
'%s%s' % (self.live_server_url, "/")
)
self.selenium.find_element_by_link_text("hello").click()
self.assertIn("hello", self.selenium.title)需要注意的是,如果我们的单元测试如果可以测试到页面的内容——即没有使用JavaScript对页面的内容进行修改,那么我们应该使用单元测试即可。如测试金字塔所说,越底层的测试越快。
在我们编写完这些测试后,我们就可以搭建好相应的持续集成来运行这些测试了。
这里我们将使用Jenkins来完成这部分的工作,它是一个用Java编写的开源的持续集成工具。
它提供了软件开发的持续集成服务。它运行在Servlet容器中(例如Apache Tomcat)。它支持软件配置管理(SCM)工具(包括AccuRev SCM、CVS、Subversion、Git、Perforce、Clearcase和和RTC),可以执行基于Apache Ant和Apache Maven的项目,以及任意的Shell脚本和Windows批处理命令。
要使用Jenkins,只需要从Jenkins的主页上(https://jenkins.io/)下载最新的 jenkins.war文件。然后运行
java -jar jenkins.war便可以启动:
Running from: /Users/fdhuang/repractise/growth-ci/jenkins.war
webroot: $user.home/.jenkins
May 12, 2016 10:55:18 PM org.eclipse.jetty.util.log.JavaUtilLog info
INFO: Logging initialized @489ms
May 12, 2016 10:55:18 PM winstone.Logger logInternal
INFO: Beginning extraction from war file
May 12, 2016 10:55:20 PM org.eclipse.jetty.util.log.JavaUtilLog warn
WARNING: Empty contextPath
May 12, 2016 10:55:20 PM org.eclipse.jetty.util.log.JavaUtilLog info
INFO: jetty-9.2.z-SNAPSHOT
May 12, 2016 10:55:20 PM org.eclipse.jetty.util.log.JavaUtilLog info
INFO: NO JSP Support for /, did not find org.eclipse.jetty.jsp.JettyJspServlet
Jenkins home directory: /Users/fdhuang/.jenkins found at: $user.home/.jenkins
May 12, 2016 10:55:21 PM org.eclipse.jetty.util.log.JavaUtilLog info
INFO: Started w.@68c34b0{/,file:/Users/fdhuang/.jenkins/war/,AVAILABLE}{/Users/fdhuang/.jenkins/war}
May 12, 2016 10:55:21 PM org.eclipse.jetty.util.log.JavaUtilLog info
INFO: Started ServerConnector@733a9ac6{HTTP/1.1}{0.0.0.0:8080}接着,打开http://0.0.0.0:8080/就可以进行后续的安装,如下图所示:
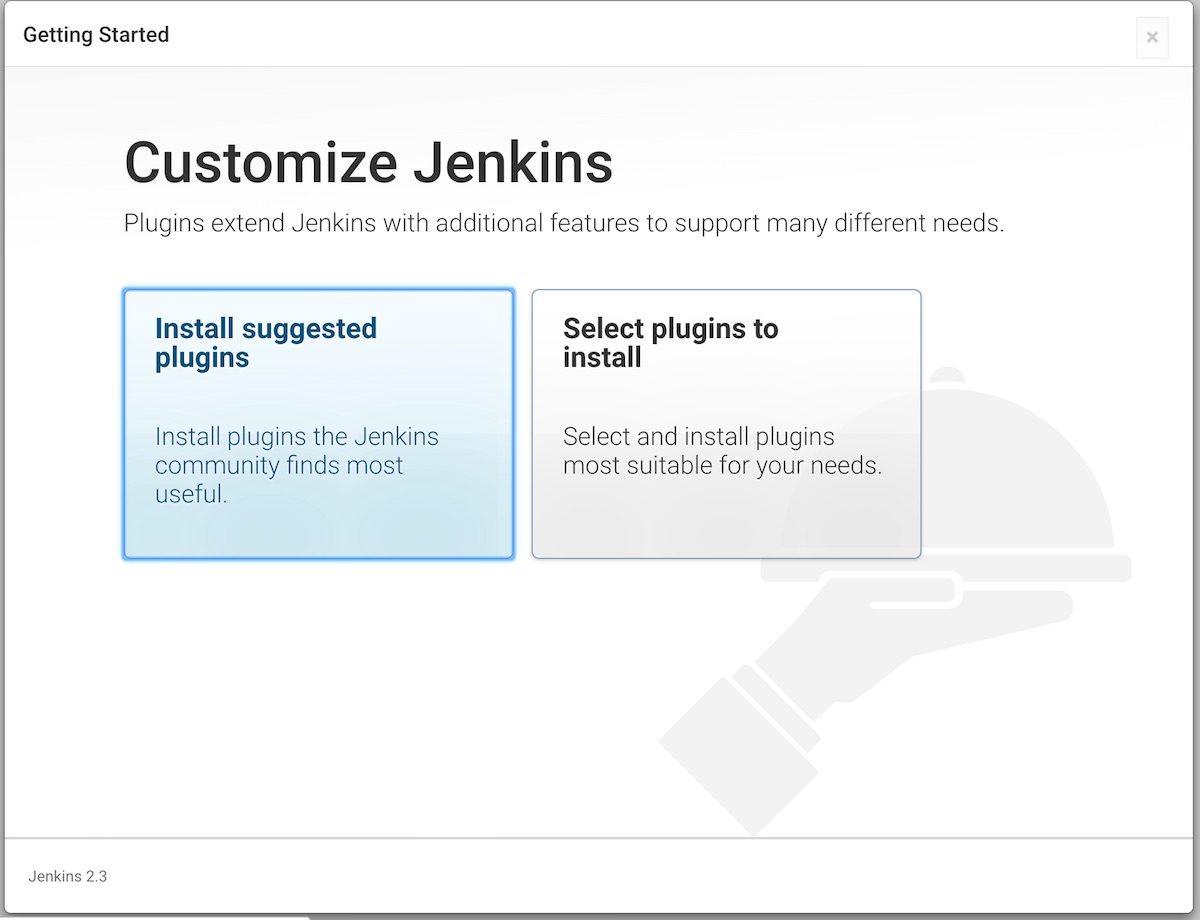
慢慢等其安装完成:
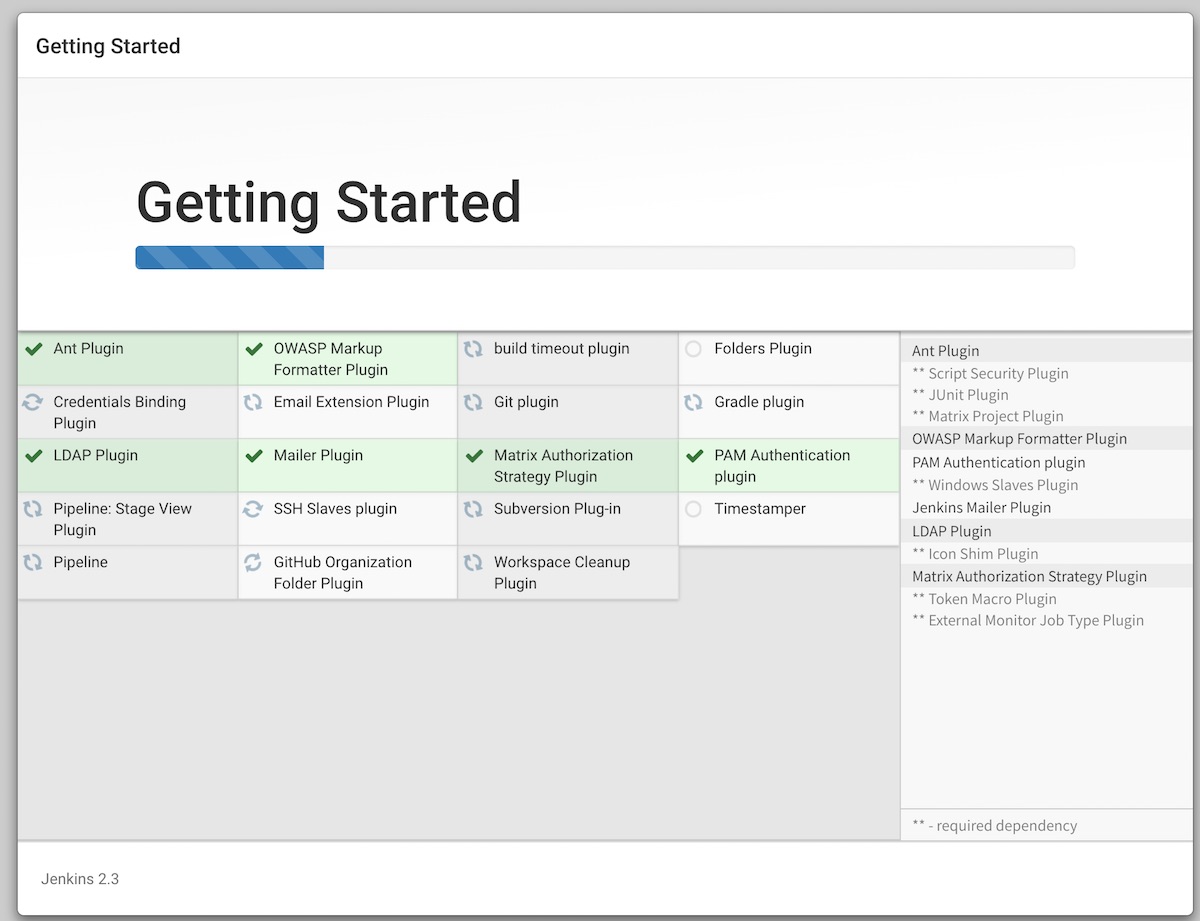
等安装完成后,我们就可以开始使用Jenkins来创建我们的任务了。
在首页,我们会看到“开始创建一个新任务”的提示,点击它。
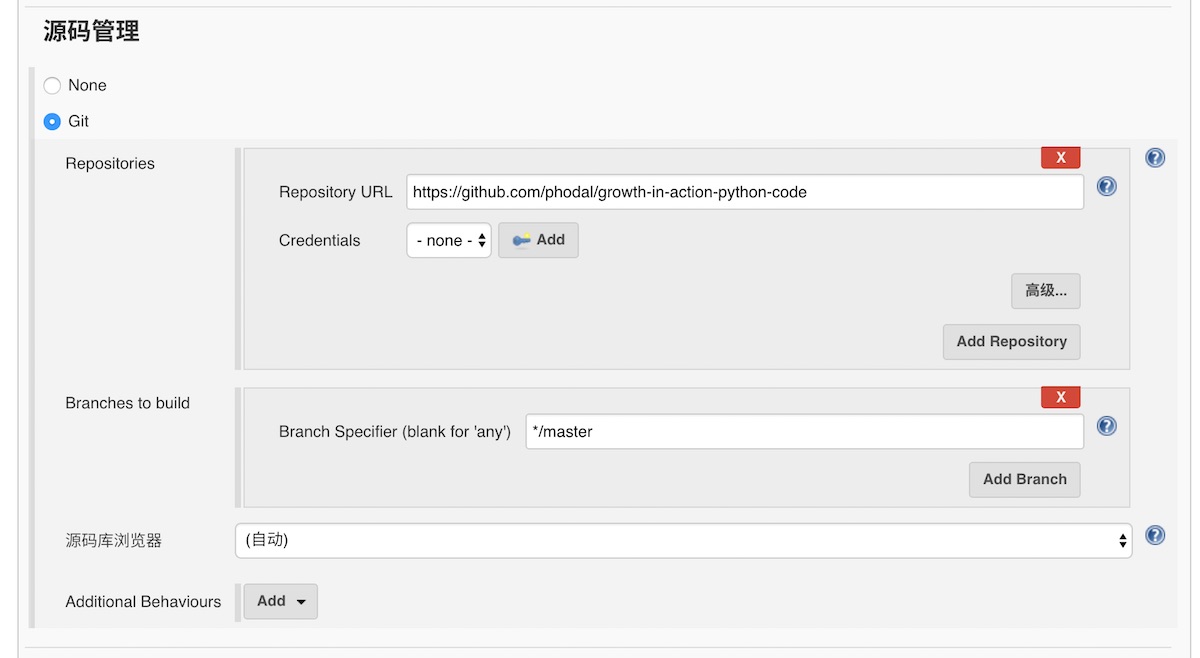
源码管理中选择Git,并填入我们代码的地址:
[https://github.com/phodal/growth-in-action-python-code](https://github.com/phodal/growth-in-action-python-code)如下图所示:
然后就是构建触发器,一共有五种类型的触发器,意思也很容易理解:
在这里,我们要使用的是GitHub这个,它的原理是:
This job will be triggered if jenkins will receive PUSH GitHub hook from repo defined in scm section
即Jenkins在监听GitHub上对应的PUSH hook,当发生代码提交时,就会运行我们的测试。
由于,我们暂时不需要一些特殊的构建环境配置,我们就可以将这个放空。接着,我们就可以配置构建了。
在这里我们需要添加的构建步骤是:execute shell,先让我们写一个简单的安装依赖的shell
virtualenv --distribute -p /usr/local/bin/python3.5 growth-django
source growth-django/bin/activate
pip install -r requirements.txt然后在保存后,我们可以尝试立即构建这个项目:

在编写shell的过程中,我们要经过一些尝试,在这其中会经历一些失败的情形——即使是大部分有相关经验的程序员。如下图就是一次编写构建脚本引起的构建失败的例子:

最后,我们就得到下面的一个shell脚本,我们就可以将其变成相应的运行CI的脚本。以便于它可以在其他环境中使用:
#!/usr/bin/env bash
virtualenv --distribute -p /usr/local/bin/python3.5 growth-django
source growth-django/bin/activate
pip install -r requirements.txt
python manage.py test
python manage.py test test记得给你的shell文件,加上执行的标志:
chmod u+x ./scripts/ci.sh最后,我们就可以修改CI上相应的构建环境的配置。
在Django框架中,内置了很多应用在它的“contrib”包中,这些包括:
这意味着,我们可以直接用Django一些内置的组件来完成很多功能,先让我们来看看怎么完成一个简单的评论功能。
Django带有一个可选的“flatpages”应用,可以让我们存储简单的“扁平化(flat)”页面在数据库中,并且可以通过Django的管理界面以及一个Python API来处理要管理的内容。这样的一个静态页面,一般包含下面的几个属性:
为了使用它来创建静态页面,我们需要在数据库中存储对应的映射关系,并创建对应的静态页面。
为此我们需要添加两个应用到settings.py文件的INSTALLED_APPS中:
django.contrib.sites——“sites”框架,它用于将对象和功能与特定的站点关联。同时,它还是域名和你的Django 站点名称之间的对应关系所保存的位置,即我们需要在这个地方设置我们的网站的域名。django.contrib.flatpages,即上文说到的内容。在添加django.contrib.sites的时候,我们需要创建一个SITE_ID。通过这个值等于1,除非我们打算用这个框架去管理多个站点。代码如下所示:
SITE_ID = 1
INSTALLED_APPS = (
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'django.contrib.sites',
'django.contrib.flatpages',
'blogpost'
)接着,还添加对应的中间件django.contrib.flatpages.middleware.FlatpageFallbackMiddleware到settings.py文件的MIDDLEWARE_CLASSES中。
然后,我们需要创建对应的URL来管理所有的静态页面。下面的代码是将静态页面都放在pages路径下,即如果我们有一个about的页面,那么对应的URL会变成 http://localhost/pages/about/。
url(r'^pages/', include('django.contrib.flatpages.urls')),当然我们也可以将其配置为类似于 http://localhost/about/ 这样的URL:
urlpatterns += [
url(r'^(?P<url>.*/)$', views.flatpage),
]最后,我们还需要做一个数据库迁移:
Operations to perform:
Apply all migrations: contenttypes, auth, admin, sites, blogpost, sessions, flatpages, django_comments
Running migrations:
Rendering model states... DONE
Applying flatpages.0001_initial... OK接着,我们可以在templates目录下创建flatpages文件,用于存放我们的模板文件,下面是一个简单的模板:
{% extends 'base.html' %}
{% block title %}关于我{% endblock %}
{% block content %}
<div>
<h2>关于博客</h2>
<p>一方面,找到更多志同道合的人;另一方面,扩大影响力。</p>
<p>内容包括</p>
<ul>
<li>成长记录</li>
<li>技术笔记</li>
<li>生活思考</li>
<li>个人试验</li>
</ul>
</div>
{% endblock %}当我们完成模板后,我们就需要登录后台,并添加对应的静态页面的配置:
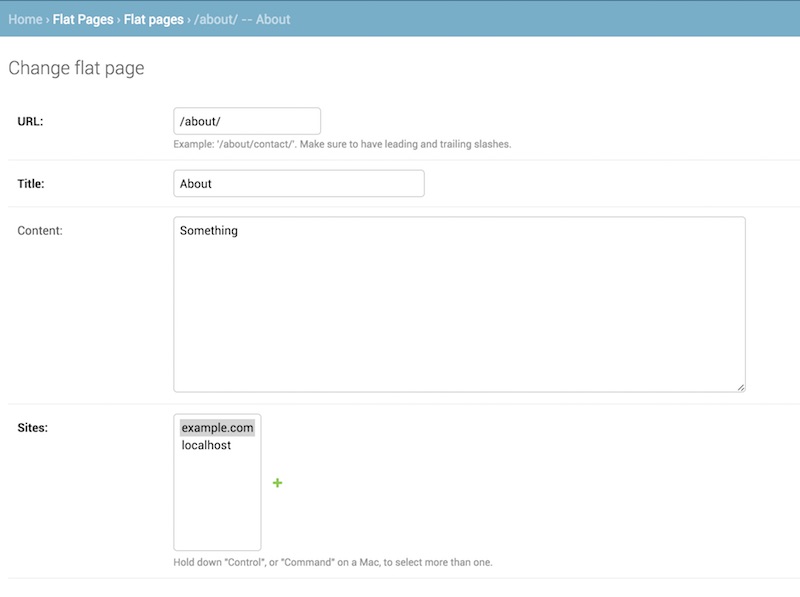
然后从高级选项中填写我们的静态页面的路径,我们就可以完成静态页面的创建。如下图所示:
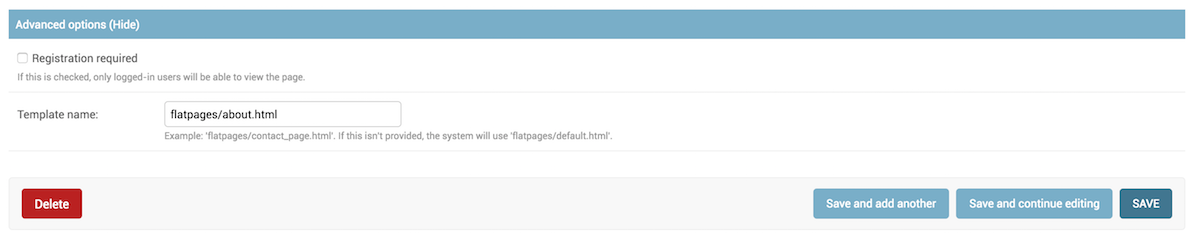
最后,还要有个链接加到首页的导航中:
<li>
<a href="/pages/about/">关于我</a>
</li>下面让我们为我们的博客添加一个简单的评论功能吧!
在早期的Django版本(1.6以前)中,Comments是自带的组件,但是后来它被从标准组件中移除了。因此,我们需要安装comments这个包:
pip install django-contrib-comments再把它及它的版本添加到requirements.txt,如下所示:
django==1.9.4
selenium==2.53.1
fabric==1.10.2
djangorestframework==3.3.3
djangorestframework-jwt==1.7.2
django-cors-headers==1.1.0
django-contrib-comments==1.7.1接着,将django.contrib.sites和django_comments添加到INSTALLED_APPS,如下:
INSTALLED_APPS = (
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'django.contrib.sites',
'django_comments',
'rest_framework',
'blogpost'
)然后做一下数据库迁移我们就可以完成对其的初始化:
Operations to perform:
Apply all migrations: contenttypes, admin, blogpost, auth, sites, sessions, django_comments
Running migrations:
Rendering model states... DONE
Applying sites.0001_initial... OK
Applying django_comments.0001_initial... OK
Applying django_comments.0002_update_user_email_field_length... OK
Applying django_comments.0003_add_submit_date_index... OK
Applying sites.0002_alter_domain_unique... OK
(growth-django)然后再添加URL到urls.py:
url(r'^comments/', include('django_comments.urls')),现在,我们就可以登录后台,来创建对应的评论,但是这是时候评论是不会显示到页面上的。所以我们需要对我们的博客详情页的模板进行修改,在其中添加一句:
{% render_comment_list for post %}用于显示对应博客的评论,最近我们的模板文件如下面的内容所示:
{% extends 'base.html' %}
{% load comments %}
{% block head_title %}{{ post.title }}{% endblock %}
{% block title %}{{ post.title }}{% endblock %}
{% block content %}
<div class="mdl-card mdl-shadow--2dp">
<div class="mdl-card__title">
<h2 class="mdl-card__title-text"><a href="{{ post.get_absolute_url }}">{{ post.title }}</a></h2>
</div>
<div class="mdl-card__supporting-text">
{{post.body}}
</div>
<div class="mdl-card__actions">
{{post.posted}} - By {{post.author}}
</div>
</div>
{% render_comment_list for post %}
{% endblock %}遗憾的是,当我们刷新页面的时候,页面报错了,原因如下所示:
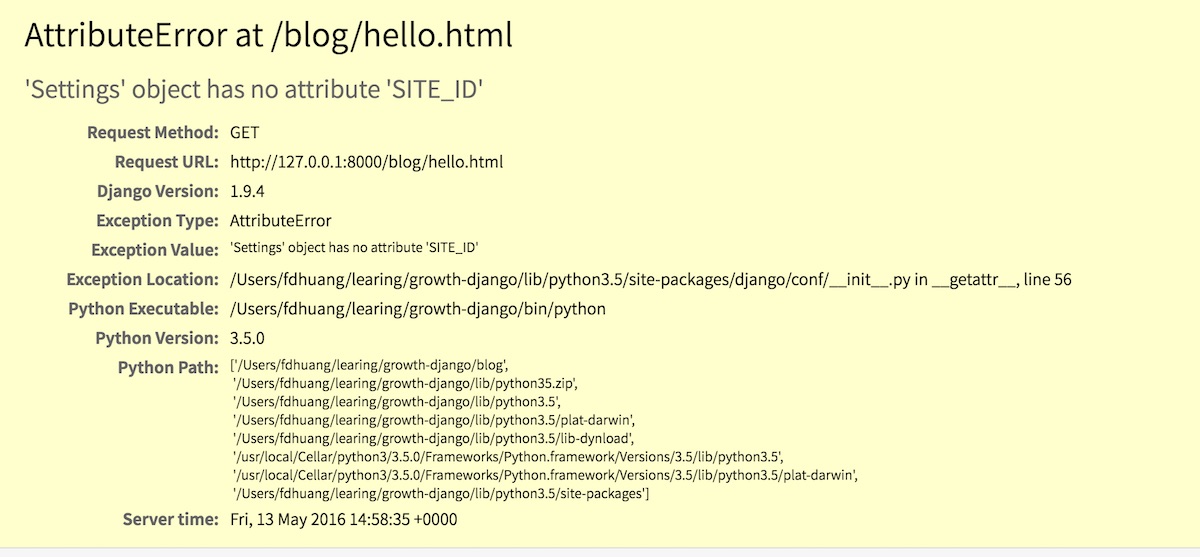
我们还需要定义一个SITE_ID,添加下面的代码到settings.py文件中即可:
SITE_ID = 1然后,我们就可以从后台创建评论:

我们在之前的文章中提到过SEO的重要性,这里只是简单地对Sitemap的内容进行展开。
Sitemap译为站点地图,它用于告诉搜索引擎他们网站上有哪些可供抓取的网页。常见的Sitemap的形式是以xml出现了,如下是我博客的sitemap.xml的一部分内容:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://www.phodal.com/blog/mezzanine-add-new-page/</loc>
<lastmod>2014-08-03</lastmod>
<changefreq>Monthly</changefreq>
<priority>0.2</priority>
</url>
</urlset>从上面的内容中,我们可以发现它包含了下面的一些XML标签:
always、hourly、daily、weekly、monthly、yearly、never从上面的内容中,我们可以发现:
站点地图能够提供与其中列出的网页相关的宝贵元数据:元数据是网页的相关信息,例如网页的最近更新时间、网页的更改频率以及网页相较于网站中其他网址的重要程度。 ——内容来自 Google Sitemap帮助文档。
现在,我们一共有三种类型的页面:
changefreq可以设置为daily、weekly,这取决于你的博客的更新频率。如果你是做一些UGC(用户生成内容)的网站,那么你应该设置为always、hourly。yearly或者monthly——并且没有高的必要性,它会导致搜索引擎一直抓取你的内容。这会对服务器造成一定的压力,并且无助于你网站的排名。priority,但是它的changefreq也不一定很高。下面就让我们从首页说起。
与上面创建静态页面时一样,我们也需要添加django.contrib.sitemaps到INSTALLED_APPS中。
然后,我们需要指定一个URL规则。通常来说,这个URL是叫sitemap.xml——一个约定俗成的标准。我们需要创建一个sitemaps对象来存储所有的sitemaps:
url(r'^sitemap\.xml$', sitemap, {'sitemaps': sitemaps}, name='django.contrib.sitemaps.views.sitemap')由于,我们使用的视图处理方法是django.contrib.sitemaps.views.sitemap,代码如下所示:
@x_robots_tag
def sitemap(request, sitemaps, section=None,
template_name='sitemap.xml', content_type='application/xml'):
req_protocol = request.scheme
req_site = get_current_site(request)在这个方法里,它指定了默认模板的位置,即在template目录中。
现在,我们需要创建几种不同类型的sitemap,如下是首页的Sitemap,它继承自Django的Sitemap类:
class PageSitemap(Sitemap):
priority = 1.0
changefreq = 'daily'
def items(self):
return ['main']
def location(self, item):
return reverse(item)它定义了自己的priority是最高的1.0,同时每新频率为daily。然后在items里面去取它所要获取的URL,即urls.py中对应的name的main的URL。在这里我们只返回了main一个值,依据于下面的location方法中的reverse,它找到了main对应的URL,即首页。
最后结合首页sitemap.xml的urls.py代码如下所示:
from sitemap.sitemaps import PageSitemap
sitemaps = {
"page": PageSitemap
}
urlpatterns = patterns('',
url(r'^$', blogpostViews.index, name='main'),
url(r'^blog/(?P<slug>[^\.]+).html', 'blogpost.views.view_post', name='view_blog_post'),
url(r'^comments/', include('django_comments.urls')),
url(r'^admin/', include(admin.site.urls)),
url(r'^pages/', include('django.contrib.flatpages.urls')),
url(r'^sitemap\.xml$', sitemap, {'sitemaps': sitemaps}, name='django.contrib.sitemaps.views.sitemap')
) + static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)除此,我们还需要创建自己的sitemap.xml模板——自带的系统模板比较简单。
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
{% spaceless %}
{% for url in urlset %}
<url>
<loc>{{ url.location }}</loc>
{% if url.lastmod %}<lastmod>{{ url.lastmod|date:"Y-m-d" }}</lastmod>{% endif %}
{% if url.changefreq %}<changefreq>{{ url.changefreq }}</changefreq>{% endif %}
{% if url.priority %}<priority>{{ url.priority }}</priority>{% endif %}
</url>
{% endfor %}
{% endspaceless %}
</urlset>最后,我们访问http://localhost:8000/sitemap.xml,我们就可以获取到我们的sitemap.xml:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>http://www.phodal.com/</loc>
<changefreq>daily</changefreq>
<priority>1.0</priority>
</url>
</urlset>下一步,我们仍可以直接创建出对应的静态页面的Sitemap。
相似的,我们也需要从items方法中,定义出我们所要创建页面的对象。
from django.contrib.sitemaps import Sitemap
from django.core.urlresolvers import reverse
from django.apps import apps as django_apps
class FlatPageSitemap(Sitemap):
priority = 0.8
def items(self):
Site = django_apps.get_model('sites.Site')
current_site = Site.objects.get_current()
return current_site.flatpage_set.filter(registration_required=False)只不过这个方法可能会稍微麻烦一些,我们需要从数据库中取出当前的站点。再取出当前站点中的flatpage集合,对过滤那些不需要注册的页面,即代码中的registration_required=False。
最后再将这个对象放入sitemaps即可:
from sitemap.sitemaps import PageSitemap, FlatPageSitemap
sitemaps = {
"page": PageSitemap,
'flatpages': FlatPageSitemap
}现在,我们可以完成博客的Sitemap了。
同上面一样的是,我们依然需要在items方法中返回所有的博客内容。并且在lastmod中,返回这篇博客的发表日期——以免他们返回的是同一个日期:
class BlogSitemap(Sitemap):
changefreq = "never"
priority = 0.5
def items(self):
return Blogpost.objects.all()
def lastmod(self, obj):
return obj.posted最近我们的Sitemap.xml,如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>http://www.phodal.com/about/</loc>
<priority>0.8</priority>
</url>
<url>
<loc>http://www.phodal.com/</loc>
<changefreq>daily</changefreq>
<priority>1.0</priority>
</url>
<url>
<loc>http://www.phodal.com/blog/hello.html</loc>
<lastmod>2016-03-24</lastmod>
<changefreq>never</changefreq>
<priority>0.5</priority>
</url>
</urlset>这里我们以Google Webmaster为例简单的介绍一下如何使用各种站长工具来提交sitemap.xml。
我们可以登录Google的Webmaster:https://www.google.com/webmasters/tools/home?hl=zh-cn,然后点击添加属性来创建一个新的网站:
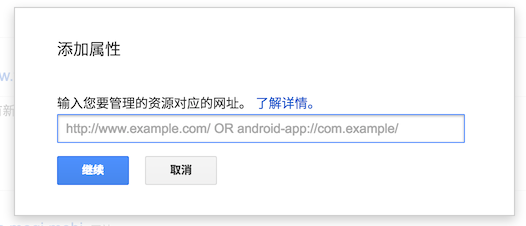
这时候Google需要确认这个网站是你的,所以它提供几种方法来验证,除了下面的推荐方法:
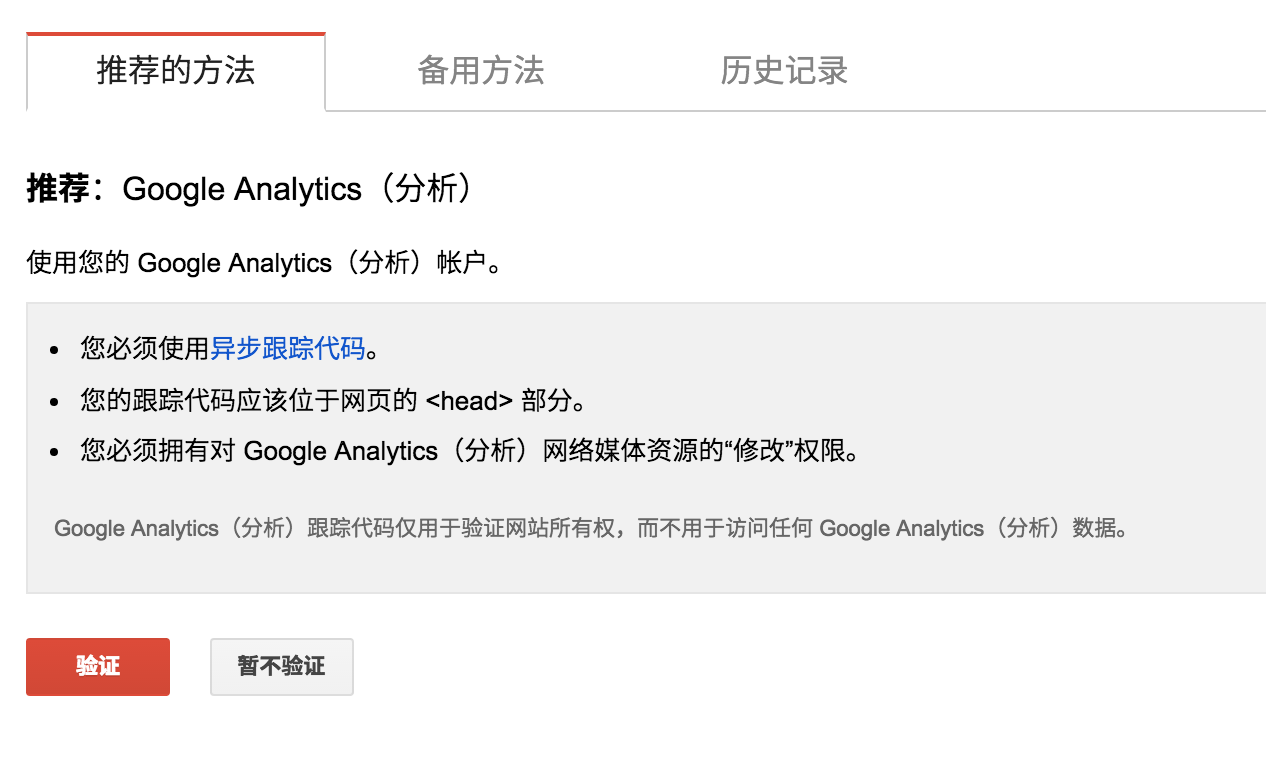
我们可以使用下面的这一些方法:

我个人比较喜欢用HTML Tag的方式来实现
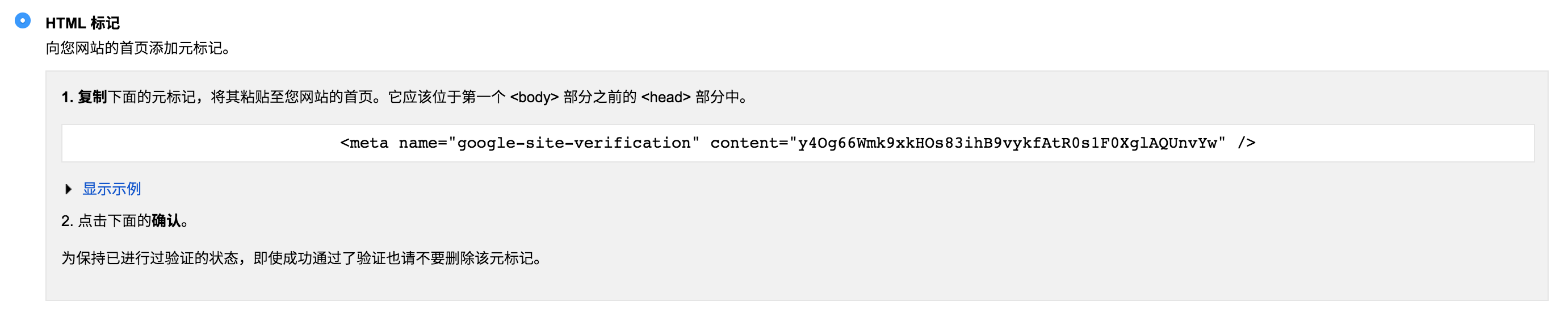
在我们完成验证之后,我们就可以在后台手动提交Sitemap.xml了。
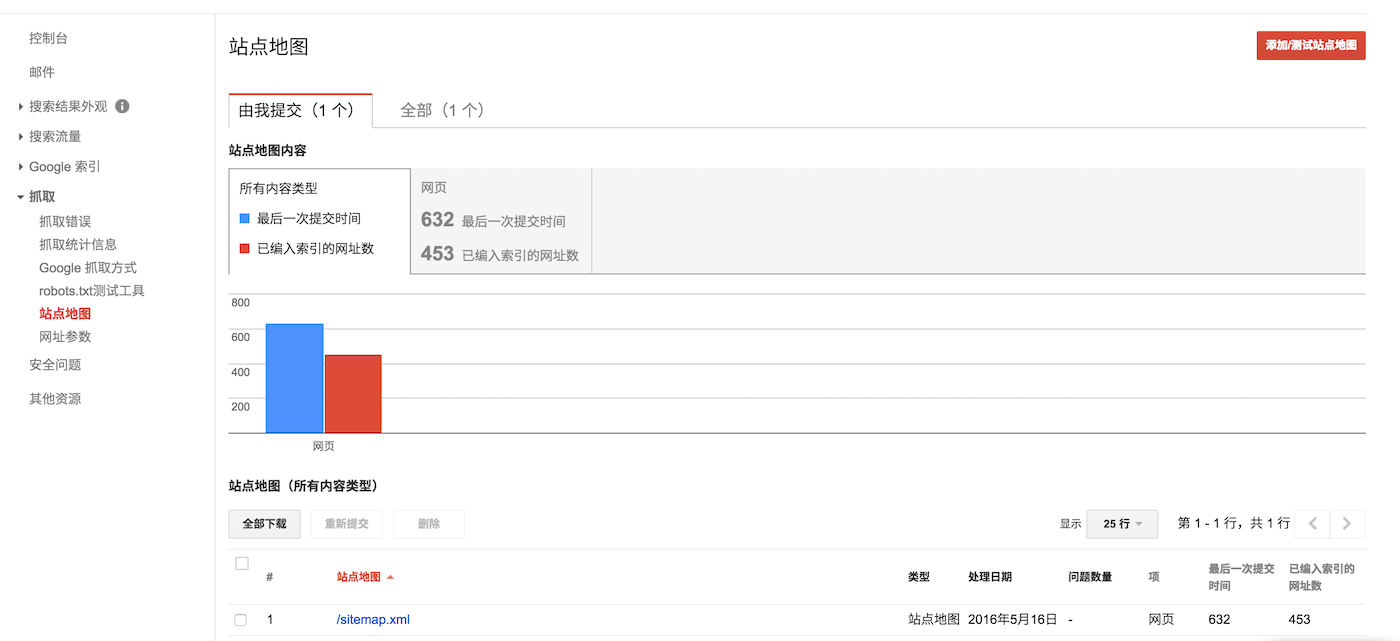
点击上方的添加/测试站点地图即可。
我们的前端样式实在是太丑了,让我们想办法来美化一下它们吧——这时候我们就需要一个前端框架来帮助我们做这件事。这里的前端框架并不是指那种MV*框架,而是UI框架。
考虑到易学程度,以其响应式设计的问题,我们决定用Bootstrap来作为这里的前端框架。Bootstrap是Twitter推出的一个用于前端开发的开源工具包,似乎也是当前“最受欢迎”的前端框架。它提供了全面、美观的文档。你能在这里找到关于 HTML 元素、HTML 和 CSS 组件、jQuery 插件方面的所有详细文档。并且我们能在 Bootstrap 的帮助下通过同一份代码快速、有效适配手机、平板、PC 设备。
它是一个支持响应式设计的框架,即页面的设计与开发应当根据用户行为以及设备环境(系统平台、屏幕尺寸、屏幕定向等)进行相应的响应和调整。如下图所示:

我们在不同的设计上看到的是不同的布局,这会依据我们的设备大小做出调整——使用媒体查询(media queries)实现。
下好Bootstrap,将里面的内容复制到static/目录,如下所示:
.
├── css
│ ├── bootstrap-theme.css
│ ├── bootstrap-theme.css.map
│ ├── bootstrap-theme.min.css
│ ├── bootstrap-theme.min.css.map
│ ├── bootstrap.css
│ ├── bootstrap.css.map
│ ├── bootstrap.min.css
│ ├── bootstrap.min.css.map
│ └── styles.css
├── fonts
│ ├── glyphicons-halflings-regular.eot
│ ├── glyphicons-halflings-regular.svg
│ ├── glyphicons-halflings-regular.ttf
│ ├── glyphicons-halflings-regular.woff
│ └── glyphicons-halflings-regular.woff2
└── js
├── bootstrap.js
├── bootstrap.min.js
└── npm.js它包含了JavaScript、CSS还有字体,需要注意的一点是bootstrap依赖于jquery。因此,我们需要下载jquery并放到这个目录里。然后在我们的head里引入这些css
<head>
<title>{% block head_title %}Welcome to my blog{% endblock %}</title>
<link rel="stylesheet" type="text/css" href="{% static 'css/bootstrap.min.css' %}">
</head>在我们的body结尾的地方:
<script src="{% static 'js/jquery.min.js' %}"></script>
<script src="{% static 'js/bootstrap.min.js' %}"></script>
</body>
</html>在这里,将Script放在body的尾部有利于用户打开页面的速度。而对于一些纯前端的框架来说,它们就需要放在页面开始的地方。
现在,我们就可以创建一个导航了。
根据Bootstrap的官方文档的Demo,我们可以创建对应的导航。
<header class="navbar navbar-static-top bs-docs-nav" id="top" role="banner">
<div class="container">
<div class="navbar-header">
<button class="navbar-toggle collapsed" type="button" data-toggle="collapse"
data-target=".bs-navbar-collapse">
<span class="sr-only">切换视图</span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
</button>
<a href="/" class="navbar-brand">Growth博客</a>
</div>
<nav class="collapse navbar-collapse bs-navbar-collapse" role="navigation">
<ul class="nav navbar-nav">
<li>
<a href="/pages/about/">关于我</a>
</li>
<li>
<a href="/pages/resume/">简历</a>
</li>
</ul>
<ul class="nav navbar-nav navbar-right">
<li><a href="/admin" id="loginLink">登入</a></li>
</ul>
</nav>
</div>
</header>它在桌面下的效果大致如下图所示:

而在移动浏览器下则是这样的效果:

当我们点击右上角的菜单按钮时,会出现我们的菜单

接着,我们可以快速的创建一个标语:
<main class="bs-docs-masthead" id="content" role="main">
<div class="container">
<div id="carbonads-container">
THE ONLY FAIR IS NOT FAIR <br>
ENJOY CREATE & SHARE
</div>
</div>
</main>这里的代码都比较简单,我想也不需要太多的解释。
接着,我们可以简单的对首页的博客列表做一个优化,方法比较简单:
row的class,表示它可以滚动col-sm-4的class,在不同的大小下会有不同的布局代码如下所示:
{% extends 'base.html' %}
{% block title %}Welcome to my blog{% endblock %}
{% block content %}
<h2>博客</h2>
<div class="row">
{% if posts %}
{% for post in posts %}
<div class="col-sm-4">
<h2><a href="{{ post.get_absolute_url }}">{{ post.title }}</a></h2>
{{post.body | slice:":80"}}
{{post.posted}} - By {{post.author}}
</div>
{% endfor %}
{% else %}
<p>There are no posts.</p>
{% endif %}
</div>
{% endblock %}它在桌面和自动设备上的效果如下图所示:


最后,我们可以在页面的最下方添加一个footer,来做一些版权声明:
<footer class="footer">
<div class="container">
<p class="text-muted">@Copyright Phodal.com</p>
</div>
</footer>它拥有一些简单的样式,来将footer固定在页面的最下方:
.footer {
position: absolute;
bottom: 0;
width: 100%;
/* Set the fixed height of the footer here */
height: 60px;
background-color: #f5f5f5;
}
.footer .container {
width: auto;
max-width: 680px;
padding: 0 15px;
}
.footer .container .text-muted {
margin: 20px 0;
}在下一章开始之前,我们先来搭建一下API平台,不仅仅可以提供一些额外的功能,还可以为我们的APP提供API。
在这里,我们需要用到一个名为Django REST Framework的RESTful API库。通过这个库,我们可以快速创建我们所需要的API。
Django REST Framework 这个名字很直白,就是基于 Django 的 REST 框架。因此,首先我们仍是要安装这个库:
pip install djangorestframework然后把它添加到INSTALLED_APPS中:
INSTALLED_APPS = (
...
'rest_framework',
)如下所示:
INSTALLED_APPS = (
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework',
'blogpost'
)接着我们可以在我们的API中创建一个URL,用于匹配它的授权机制。
urlpatterns = [
...
url(r'^api-auth/', include('rest_framework.urls', namespace='rest_framework'))
]不过这个API,目前并没有多大的用途。只有当我们在制作一些需要权限验证的接口时,它才会突显它的重要性。
为了方便我们继续展开后面的内容,我们先来创建一个博客列表API。参考Django REST Framework的官方文档,我们可以很快地创建出下面的Demo:
from django.contrib.auth.models import User
from rest_framework import serializers, viewsets
from blogpost.models import Blogpost
class BlogpsotSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = Blogpost
fields = ('title', 'author', 'body', 'slug')
class BlogpostSet(viewsets.ModelViewSet):
queryset = Blogpost.objects.all()
serializer_class = BlogpsotSerializer在上面这个例子中,API由两个部分组成:
我们在我们的URL中,会定义相应的规则到ViewSet,而ViewSet则通过serializer_class找到对应的Serializers。我们将Blogpost的所有对象赋予queryset,并返回这些值。在BlogpsotSerializer中,我们定义了我们要返回的几个字段:title、author、body、slug。
接着,我们可以在我们的urls.py配置URL。
...
from rest_framework import routers
from blogpost.api import BlogpostSet
apiRouter = routers.DefaultRouter()
apiRouter.register(r'blogpost', BlogpostSet)
urlpatterns = [,
...
url(r'^api/', include(apiRouter.urls)),
] + static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)我们使用默认的Router来配置我们的URL,即DefaultRouter,它提供了一个非常简单的机制来自动检测URL规则。因此,我们只需要注册好我们的url——blogpost以及它值BlogpostSet即可。随后,我们再为其定义一个根URL即可:
url(r'^api/', include(apiRouter.urls))现在,我们可以访问http://127.0.0.1:8000/api/来访问我们现在的API。由于Django REST Framework提供了一个UI机制,所以我们可以在网页上直接看到我们所有的API:
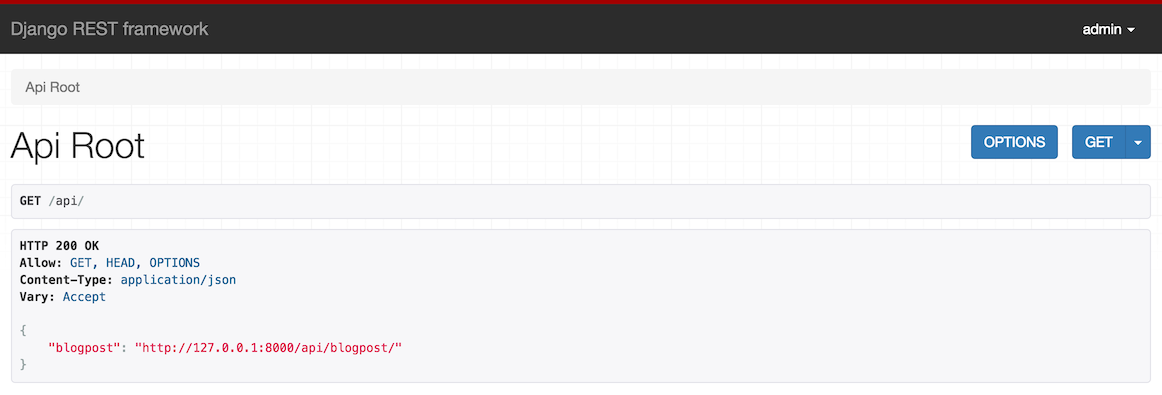
然后,点击页面中的http://127.0.0.1:8000/api/blogpost/,我们就可以访问博客相关的API了,如下图所示:
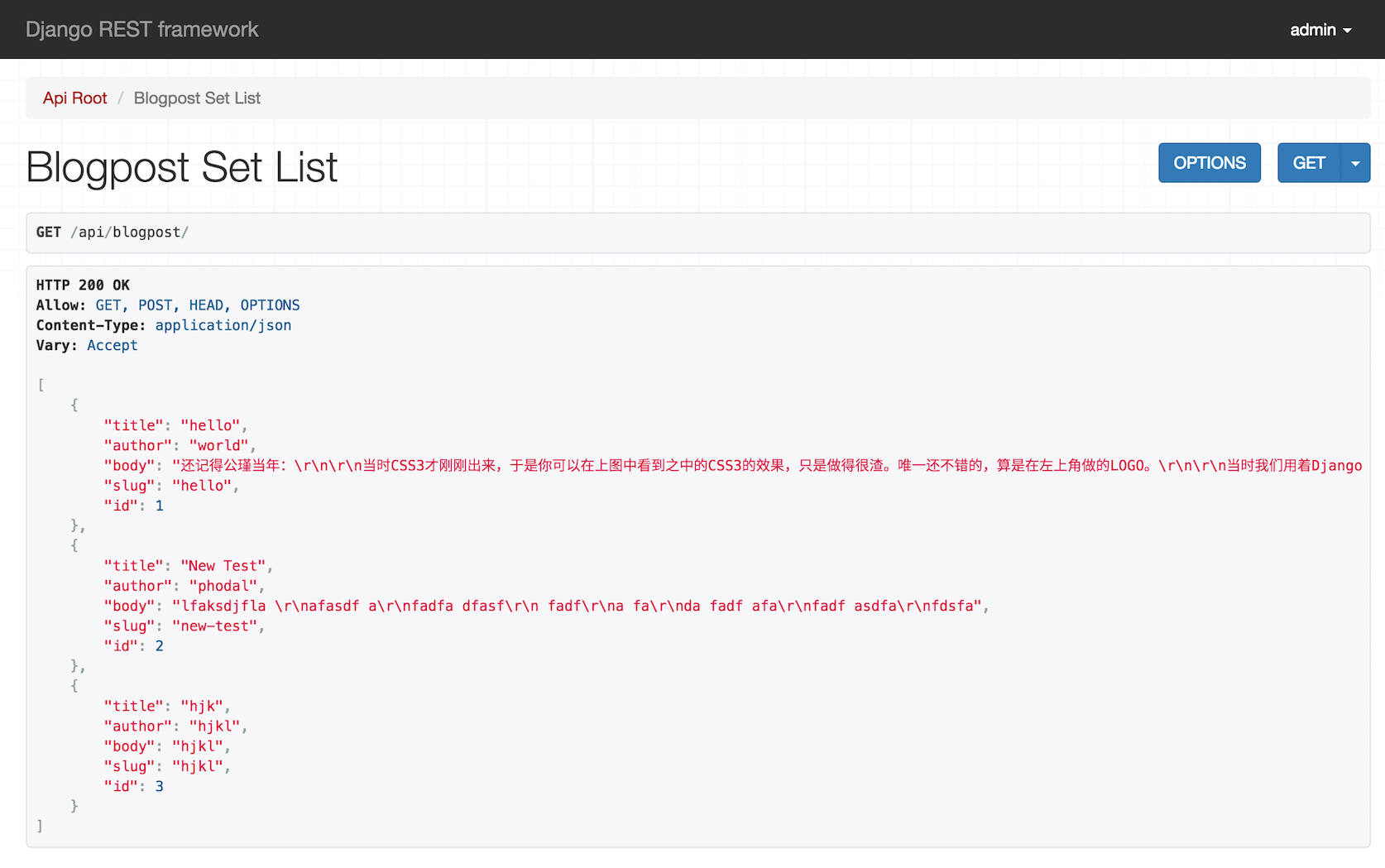
在页面上显示了所有的博客内容,在页面的下面有一个表单可以先让我们来创建数据:
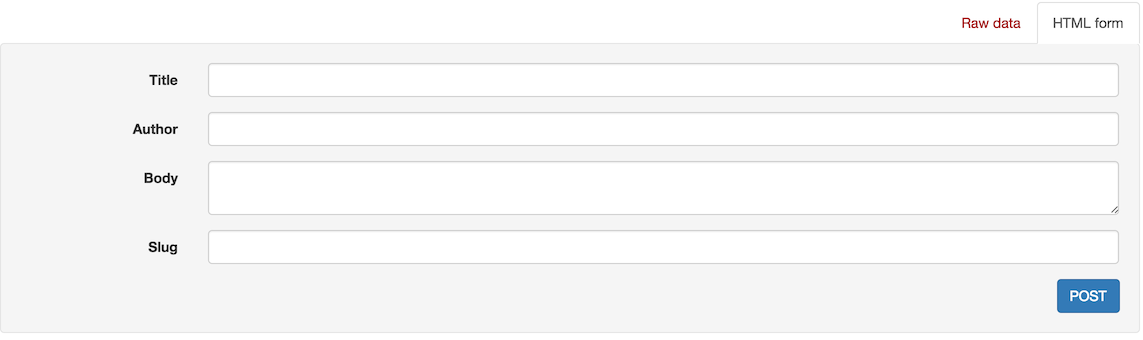
直接在表单中添加数据,我们就可以完成数据创建了。
当然,我们也可以直接用命令行工具来测试,执行:
curl -i http://127.0.0.1:8000/api/blogpost/即可返回相应的结果:

AutoComplete是一个很有意思的功能,特别是当我们的文章很多的时候,我们可以让读者有机会能搜索到相应的功能。以Google为例,Google在我们输入一些关键字的时候,会向我们推荐一些比较流行的词条可以让我们选择。
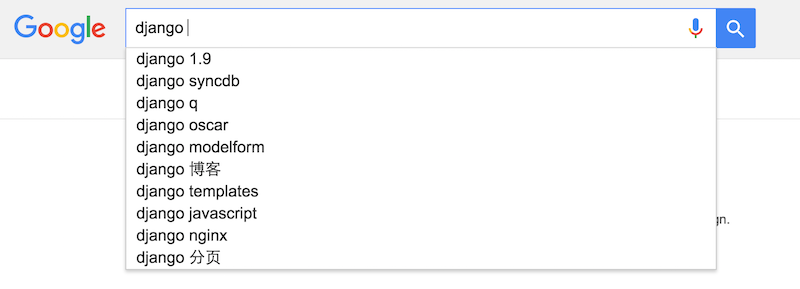
同样的,我们也可以实现一个同样的效果用于我们的博客搜索:
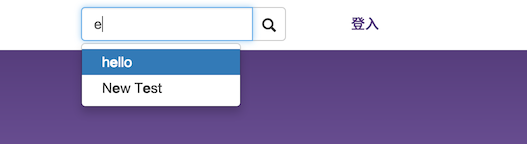
当我们输入某一些关键字的时候,就会出现文章的标题,随后我们只需要点击相应的标题即可跳转到文章。
为了实现这个功能我们需要对之前的博客API做一些简单的改造——可以支持搜索博客标题。这里我们需要稍微扩展一下我们的博客API即可:
class BlogpostSet(viewsets.ModelViewSet):
permission_classes = (permissions.IsAuthenticatedOrReadOnly,)
serializer_class = BlogpsotSerializer
search_fields = 'title'
def list(self, request):
queryset = Blogpost.objects.all()
search_param = self.request.query_params.get('title', None)
if search_param is not None:
queryset = Blogpost.objects.filter(title__contains=search_param)
serializer = BlogpsotSerializer(queryset, many=True)
return Response(serializer.data)我们添加了一个名为search_fields的变量,顾名思义就是定义搜索字段。接着我们覆写了ModelViewSet的list方法,它是用于列出(list)所有的结果。我们会尝试在我们的请求中获取搜索参量,如果没有的话我们就返回所有的结果。如果搜索的参数中含有标题,则从所有博客中过滤出标题中含有搜索标题中的内容,再返回这些结果。如下是一个搜索的URL:http://127.0.0.1:8000/api/blogpost/?format=json&title=test,我们搜索标题中含有test的内容。
同时,我们还需要为我们的apiRouter设置一个basename,即下面代码中最后的Blogpost
apiRouter.register(r'blogpost', BlogpostSet, 'Blogpost')接着,我们就可以在页面上实现这个功能。在这里我们使用一个名为Bootstrap-3-Typeahead的插件来实现,下载这个插件以及它对应的CSS:https://github.com/bassjobsen/typeahead.js-bootstrap-css,并添加到base.html中,然后创建一个main.js文件负责相关的逻辑处理。
<script src="{% static 'js/jquery.min.js' %}"></script>
<script src="{% static 'js/bootstrap.min.js' %}"></script>
<script src="{% static 'js/bootstrap3-typeahead.min.js' %}"></script>
<script src="{% static 'js/main.js' %}"></script>接着我们需要在页面上创建对应的UI,我们可以直接在登录后面添加这个搜索按钮:
<nav class="collapse navbar-collapse bs-navbar-collapse" role="navigation">
<ul class="nav navbar-nav">
<li>
<a href="/pages/about/">关于我</a>
</li>
<li>
<a href="/pages/resume/">简历</a>
</li>
</ul>
<ul class="nav navbar-nav navbar-right">
<li><a href="/admin" id="loginLink">登录</a></li>
</ul>
<div class="col-sm-3 col-md-3 pull-right">
<form class="navbar-form" role="search">
<div class="input-group">
<input type="text" id="typeahead-input" class="form-control" placeholder="Search" name="search" data-provide="typeahead">
<div class="input-group-btn">
<button class="btn btn-default search-button" type="submit"><i class="glyphicon glyphicon-search"></i></button>
</div>
</div>
</form>
</div>
</nav>我们主要是使用input标签,标签上对应有一个id
<input type="text" id="typeahead-input" class="form-control" placeholder="Search" 对应于这个ID,我们就可以开始编写我们的功能了:
$(document).ready(function () {
$('#typeahead-input').typeahead({
source: function (query, process) {
return $.get('/api/blogpost/?format=json&title=' + query, function (data) {
return process(data);
});
},
updater: function (item) {
return item;
},
displayText: function (item) {
return item.title;
},
afterSelect: function (item) {
location.href = 'http://localhost:8000/blog/' + item.slug + ".html";
},
delay: 500
});
});$(document).ready()方法可以是在DOM完成加载后,运行其中的函数。接着我们开始监听#typeahead-input,对应的便是id为typeahead-input的元素。可以看到在这其中有五个对象:
虽然我们使用的是插件来完成我们的功能,但是总体的处理逻辑是:
当我们想为其他的网页提供我们的API时,可能会报错——原因是不支持跨域请求。为了方便我们下一章更好的展开,内容我们在这里对跨域进行支持。
有一个名为django-cors-headers的插件用于实现对跨域请求的支持,我们只需要安装它,并进行一些简单的配置即可。
pip install django-cors-headers安装过程如下:
Collecting django-cors-headers
Downloading django-cors-headers-1.1.0.tar.gz
Building wheels for collected packages: django-cors-headers
Running setup.py bdist_wheel for django-cors-headers ... done
Stored in directory: /Users/fdhuang/Library/Caches/pip/wheels/b0/75/89/7b17f134fc01b74e10523f3128e45b917da0c5f8638213e073
Successfully built django-cors-headers
Installing collected packages: django-cors-headers
Successfully installed django-cors-headers-1.1.0我们还需要添加到django-cors-headers=1.1.0到requirements.txt文件中,以及添加到settings.py中:
INSTALLED_APPS = (
...
'corsheaders',
...
)以及对应的中间件:
MIDDLEWARE_CLASSES = (
...
'corsheaders.middleware.CorsMiddleware',
'django.middleware.common.CommonMiddleware',
...
)同时还有对应的配置:
CORS_ALLOW_CREDENTIALS = True现在,让我们进行下一步,开始APP吧!
依照国际惯例,我们还将用Ionic 2继续创建hello,world。
开始之前我们需要先安装Ionic的命令行工具,后面我们需要用这个工具来创建工程。
npm install -g ionic@beta如果没有意外,我们将安装成功,然后可以使用ionic命令:
它自带了一系列的工具来加速我们的开发,这些工具可以在后面的章节中学习到。
Available tasks: (use --help or -h for more info)
start .......... Starts a new Ionic project in the specified PATH
serve .......... Start a local development server for app dev/testing
platform ....... Add platform target for building an Ionic app
run ............ Run an Ionic project on a connected device
emulate ........ Emulate an Ionic project on a simulator or emulator
build .......... Build (prepare + compile) an Ionic project for a given platform.
plugin ......... Add a Cordova plugin
resources ...... Automatically create icon and splash screen resources (beta)
Put your images in the ./resources directory, named splash or icon.
Accepted file types are .png, .ai, and .psd.
Icons should be 192x192 px without rounded corners.
Splashscreens should be 2208x2208 px, with the image centered in the middle.
upload ......... Upload an app to your Ionic account
share .......... Share an app with a client, co-worker, friend, or customer
lib ............ Gets Ionic library version or updates the Ionic library
setup .......... Configure the project with a build tool (beta)
io ............. Integrate your app with the ionic.io platform services (alpha)
security ....... Store your app's credentials for the Ionic Platform (alpha)
push ........... Upload APNS and GCM credentials to Ionic Push (alpha)
package ........ Use Ionic Package to build your app (alpha)
config ......... Set configuration variables for your ionic app (alpha)
browser ........ Add another browser for a platform (beta)
service ........ Add an Ionic service package and install any required plugins
add ............ Add an Ion, bower component, or addon to the project
remove ......... Remove an Ion, bower component, or addon from the project
list ........... List Ions, bower components, or addons in the project
info ........... List information about the users runtime environment
help ........... Provides help for a certain command
link ........... Sets your Ionic App ID for your project
hooks .......... Manage your Ionic Cordova hooks
state .......... Saves or restores state of your Ionic Application using the package.json file
docs ........... Opens up the documentation for Ionic
generate ....... Generate pages and components现在,我们就可以用第一个命令start来创建我们的项目。
ionic start growth-blog-app --v2在这个过程中,它将下载Ionic 2项目的基础项目,并执行安装命令。
Creating Ionic app in folder /Users/fdhuang/repractise/growth-blog-app based on tabs project
Downloading: https://github.com/driftyco/ionic2-app-base/archive/master.zip
[=============================] 100% 0.0s
Downloading: https://github.com/driftyco/ionic2-starter-tabs/archive/master.zip
[=============================] 100% 0.0s
Installing npm packages...然后到growth-blog-app目录,我们会看到类似于下面的内容:
.
├── README.md
├── app
│ ├── app.js
│ ├── pages
│ │ ├── page1
│ │ │ ├── page1.html
│ │ │ ├── page1.js
│ │ │ └── page1.scss
│ │ ├── page2
│ │ │ ├── page2.html
│ │ │ ├── page2.js
│ │ │ └── page2.scss
│ │ ├── page3
│ │ │ ├── page3.html
│ │ │ ├── page3.js
│ │ │ └── page3.scss
│ │ └── tabs
│ │ ├── tabs.html
│ │ └── tabs.js
│ └── theme
│ ├── app.core.scss
│ ├── app.ios.scss
│ ├── app.md.scss
│ ├── app.variables.scss
│ └── app.wp.scss
├── config.xml
├── gulpfile.js
├── hooks
│ ├── README.md
│ └── after_prepare
│ └── 010_add_platform_class.js
├── ionic.config.json
├── package.json
└── www
└── index.html在这2.0版本的Ionic,页面开始以目录来划分,一个页面路径下有自己的html、js、scss。
tabs负责这些页面间跳转theme则负责系统相应样式的修改config.xml带有相应的Cordova配置hooks则对系统添加和编译时进行一些预处理ionic.config.json则是ionic的一些相关配置选项package.json则存放相应的node.js的包的依赖www目录用于存放出最后构建出来的内容,以及一些静态资源由于Angular 2.0使用的是Typescript,所以在这里我们将用typescript进行展示,因此我们的执行命令变成~~:
ionic start growth-blog-app --v2 --ts--ts表示使用的是typescript来创建项目,安装的过程是一样的,不一样的是后面写的代码。
执行相应的启动serve命令,我们就可以开始我们的项目了:
ionic serve这时候Ionic将做一些额外的事,才能启动我们的服务,如:
www/build目录下的文件最后,它将启动一个Web服务,URL为http://localhost:8100
Running 'serve:before' gulp task before serve
[20:59:16] Starting 'clean'...
[20:59:16] Finished 'clean' after 6.07 ms
[20:59:16] Starting 'watch'...
[20:59:16] Starting 'sass'...
[20:59:16] Starting 'html'...
[20:59:16] Starting 'fonts'...
[20:59:16] Starting 'scripts'...
[20:59:16] Finished 'scripts' after 43 ms
[20:59:16] Finished 'html' after 51 ms
[20:59:16] Finished 'fonts' after 54 ms
[20:59:16] Finished 'sass' after 738 ms
7.6 MB bytes written (5.62 seconds)
[20:59:22] Finished 'watch' after 6.62 s
[20:59:22] Starting 'serve:before'...
[20:59:22] Finished 'serve:before' after 3.87 μs
Running live reload server: http://localhost:35729
Watching: www/**/*, !www/lib/**/*
√ Running dev server: http://localhost:8100
Ionic server commands, enter:
restart or r to restart the client app from the root
goto or g and a url to have the app navigate to the given url
consolelogs or c to enable/disable console log output
serverlogs or s to enable/disable server log output
quit or q to shutdown the server and exit
ionic $接着,就可以打开相应的Web页面,如下图所示:
由于Ionic是基于Cordova的,我们需要安装Cordova业完成后续的工作。
sudo npm install -g cordova为了构建不同的平台的应用,我们就需要添加不同的平台,如:
ionic platform add android上面的命令可以为项目添加Android平台的支持,过程如下面的日志所示:
Adding android project...
Creating Cordova project for the Android platform:
Path: platforms/android
Package: io.ionic.starter
Name: V2_Test
Activity: MainActivity
Android target: android-23
Android project created with cordova-android@5.1.1
Running command: /Users/fdhuang/repractise/growth-blog-app/hooks/after_prepare/010_add_platform_class.js /Users/fdhuang/repractise/growth-blog-app最后,再执行run就可以在对应的平台上运行,如:
ionic run android现在,让我们来结合我们的博客APP,做一个相应的展示博客的APP。在这一步我们所要做的事情比较简单:
在上一个章节里我们已经有了一个博客详细的API,我们只需要获取这个API并显示即可。不过,让我们简单地熟悉一下显示数据的这部分内容:
<ion-navbar *navbar>
<ion-title>博客</ion-title>
</ion-navbar>
<ion-content class="blog-list">
<ion-item *ngFor="#blogpost of blogposts">
<h1 *ngIf="blogpost">
{{blogpost.title}}
</h1>
<p *ngIf="blogpost">
{{blogpost.body}}
</p>
</ion-item>
</ion-content>上面是一个基本的详情页的模板,其中定义了一系列的Ionic自定义标签,如:
而从上面的内容中,我们可以看到:我们在ngFor中遍历了blogposts,然后显示每篇文章的标题和内容。对应的代码也就比较简单了:
import {Page} from 'ionic-angular';
@Page({
templateUrl: 'build/pages/blog/list/index.html',
providers: [BlogpostServices]
})
export class BlogList {
public blogposts;
constructor() {
}
}但是我们要去哪里获取博客的值呢,我们先看看改造后的BlogList的Controller:
import {Page} from 'ionic-angular';
import {BlogpostServices} from '../../../services/BlogpostServices';
@Page({
templateUrl: 'build/pages/blog/list/index.html',
providers: [BlogpostServices]
})
export class BlogList {
private blogListService;
public blogposts;
constructor(blogpostServices:BlogpostServices) {
this.blogListService = blogpostServices;
this.initService();
}
private initService() {
this.blogListService.getBlogpostLists().subscribe(
data => {this.blogposts = JSON.parse(data._body);},
err => console.log('Error: ' + JSON.stringify(err)),
() => console.log('Get Blogpost')
);
}
}我们初始化了一个blogListService,然后我们调用这个服务去获取博客列表。
this.blogListService.getBlogpostLists().subscribe(
data => {this.blogposts = JSON.parse(data._body);},
err => console.log('Error: ' + JSON.stringify(err)),
() => console.log('Get Blogpost')
);当我们获取到数据的时候,我们就解析这个数据,并将这个值赋予blogposts。如果这其中遇到什么错误,就会显示相应的错误信息。
现在,让我们创建一个获取博客的服务:
import {Inject} from 'angular2/core';
import {Http} from 'angular2/http';
import 'rxjs/add/operator/map';
export class BlogpostServices {
private http;
constructor(@Inject(Http) http:Http) {
this.http = http
}
getBlogpostLists() {
var url = 'http://127.0.0.1:8000/api/blogpost/?format=json';
return this.http.get(url).map(res => res);
}
}我们将通过这个API来获取相关的数据,并将数据返回到BlogList类中。接着将更新blogposts的值,并重新渲染页面。
在我们的博客API中,每个内容都对应有一个id,如下所示:
{
"title": "这是一个标题",
"author": "Phodal2",
"body": "这是一个测试的内容",
"slug": "this-is-a-test",
"id": 3
}我们只需要访问这个id,就可以获取这个结果,如:http://localhost:8000/api/blogpost/3/
因此,我们所需要做的就是:
好了,我们可以用ionic的生成命令来创建博客详情页。
ionic g page blog-detail --ts它将在app/pages目录下,生成下面的内容:
app/pages/blog-detail/
├── blog-detail.html
├── blog-detail.ts
└── blog-detail.scss我们可以遵循之前添加Django App的习惯,先添加Router。因此我们可以在app.ts添加新的Route:
const ROUTES = [
{path: '/app/blog/:id', component: BlogDetailPage}
];
@App({
template: '<ion-nav [root]="rootPage"></ion-nav>',
config: {}
})
@RouteConfig(ROUTES)
export class MyApp {
rootPage:any = TabsPage;
constructor(platform:Platform) {
this.rootPage = TabsPage;
this.initializeApp(platform)
}
private initializeApp(platform:Platform) {
platform.ready().then(() => {
StatusBar.styleDefault();
});
}
}我们用RouteConfig来关联我们的URL和App Component。
同上面的博客列表页面一样,我们也可以直接添加我们的API服务。有所区别的是,我们需要依据id去获取我们的博客内容。
getBlogpostDetail(id) {
var url = 'http://localhost:8000/api/blogpost/' + id + '?format=json';
return this.http.get(url).map(res => res);
}和之前的博客列表一样,我们需要几乎一样的方法来获取数据:
import {Page, NavController, NavParams} from 'ionic-angular';
import {BlogpostServices} from "../../services/BlogpostServices";
@Page({
templateUrl: 'build/pages/blog-detail/blog-detail.html',
providers: [BlogpostServices]
})
export class BlogDetailPage {
private navParams;
private blogServices;
private blogpost;
constructor(public nav:NavController, navParams:NavParams, blogServices:BlogpostServices) {
this.nav = nav;
this.navParams = navParams;
this.blogServices = blogServices;
this.initService();
}
private initService() {
let id = this.navParams.get('id');
this.blogServices.getBlogpostDetail(id).subscribe(
data => {
this.blogpost = JSON.parse(data._body);
console.log(this.blogpost);
},
err => console.log('Error: ' + JSON.stringify(err)),
() => console.log('Get Blogpost')
);
}
}现在我们几乎已经完成了博客详情页的工作,我们可以直接通过URL来访问博客详情页:http://localhost:8100/#/app/blog/1。结果如下图所示:
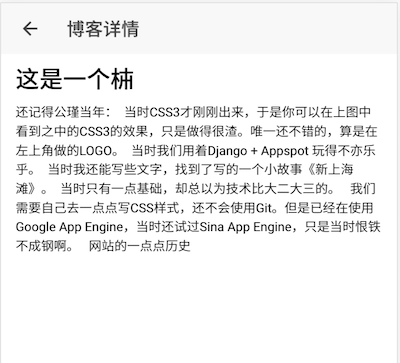
不过,这时候我们的列表页并没有和详情页关联到一起。我们还需要做一些额外的工作:
在我们的模板页里ion-item里添加一个click事件,这个事件将调用navigate函数,并把博客id传到这个函数里。
<ion-item *ngFor="#blogpost of blogposts" (click)="navigate(blogpost.id)">
<h1 *ngIf="blogpost">
{{blogpost.title}}
</h1>
<p *ngIf="blogpost">
{{blogpost.body}}
</p>
</ion-item>随后在我们的博客详情页的初始化里,我们要初始化一个NavController:
constructor(nav: NavController, blogpostServices:BlogpostServices) {
this.blogListService = blogpostServices;
this.nav = nav;
this.initService();
}接着,在navigate里我们只需要将BlogDetailPage页面及参数push给navController,并交由它来渲染页面。
navigate(id){
this.nav.push(BlogDetailPage, {
id: id
});
}现在,我们可以试试从首页跳转到这个博客详情页。
现在,我们要做一个更有意思的东西了。不过这个内容是为后面的创建文章提供一个技术基础。在用户授权这一部分,我们使用不同的技术来实现,如Cookies、HTTP基本认证等等。而在手机端继续Cookie来进行用户授权,不是一件简单的事。因此我们就需要JSON Web Tokens,这是一种基于token 的认证方案。
同样,为了实现这部分功能,我们仍然可以使用其他框架来帮助我们完成基础功能。这里我们就用到了一个名为djangorestframework-jwt的库,从它的名字上我们就可以知道,它就是基于Django REST Framework之上的JWT实现。还是继续使用pip来安装这个库,记得把它添加到requirements.txt中。
pip install djangorestframework-jwt接着,我们需要在我们的URL中配置用于获取token的API即可使用。
urlpatterns = patterns(
'',
# ...
url(r'^api-token-auth/', 'rest_framework_jwt.views.obtain_jwt_token'),
)在我们完成了上面的步骤之后,我们可以用curl命令或者Chrome浏览器的Postman来做测试:
如下是curl创建的请求,在这其中我们发送了我们的用户和密码。
curl -H "Content-Type: application/json" -X POST -d '{"username":"admin","password":"root"}' http://localhost:8000/api-token-auth然后服务端给我们返回了对应的Token,它可以用于后面的创建文章、获取用户信息等等的功能。下面是一个Token的示例:
{"token":"eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJlbWFpbCI6ImhAcGhvZGFsLmNvbSIsInVzZXJfaWQiOjIsInVzZXJuYW1lIjoiYWRtaW4iLCJleHAiOjE0NjQ4NzQ1MDZ9.B5LEeIlGDTGggD6dh9akGRKx0Hk09wjylQRLas6kjGM"}现在,我们要先做的一件事就是,创建一个用于登录的表单。
<form #loginCreds="ngForm" (ngSubmit)="login(loginCreds.value)">
<ion-item>
<ion-label>Username</ion-label>
<ion-input type="text" ngControl="username"></ion-input>
</ion-item>
<ion-item>
<ion-label>Password</ion-label>
<ion-input type="password" ngControl="password"></ion-input>
</ion-item>
<div padding>
<button block type="submit">登录</button>
</div>
</form>我们创建一个名为loginCreds的ngForm,在我们提交的时候我们就调用login方法,并把其中的值(username、password)传过去。而在我们的代码里,我们所要做的就是和上面一样将数据post到之前的Auth API的地址:
constructor(http: Http, nav:NavController) {
this.nav = nav;
this.http = http;
this.local.get('id_token').then(
(data) => {
this.user = this.jwtHelper.decodeToken(data).username;
}
);
}
login(credentials) {
this.contentHeader = new Headers({"Content-Type": "application/json"});
this.http.post(this.LOGIN_URL, JSON.stringify(credentials), {headers: this.contentHeader})
.map(res => res.json())
.subscribe(
data => this.authSuccess(data.token),
err => console.log(err)
);
}
authSuccess(token) {
this.local.set('id_token', token);
this.user = this.jwtHelper.decodeToken(token).username;
}在我们成功的获取到Token的时候,保存这个Token,并调用jwtHelper来解码Token,并从中获取我们的username。
同时,对于我们来说要登出就是一件容易的,删除这个token,将用户名清空。
logout() {
this.local.remove('id_token');
this.user = null;
}当我们获取到这个Token,我们也可以顺便获取用户的用户名、邮件等等的信息给用户。我们所要做的就是再获取一次API,但是在获取这次API的时候,我们需要上传我们的Token。因此我们需要一个简单的AuthHelper来帮助我们。
虽然我们要做的仅仅只是在我们的Header中,添加一个字段,它的值就是Token的值。但是这部分的逻辑交给Angular2-JWT来做可能会好一点,它提供了一个AuthHTTP方法可以让每次请求都带上这个Header。首先我们需要安装这个库:
npm install angular2-jwt然后在我们app.ts中添加这个provider,并指明它的header前缀是JWT。
@App({
template: '<ion-nav [root]="rootPage"></ion-nav>',
config: {}, // http://ionicframework.com/docs/v2/api/config/Config/
providers: [
provide(AuthHttp, {
useFactory: (http) => {
var authConfig = new AuthConfig({headerPrefix: 'JWT'});
return new AuthHttp(authConfig, http);
},
deps: [Http]
})
]
})现在,我们就可以用和Http一样的方式去获取用户信息。
现在我们所需要做的就是发出我们的API去获取用户的信息:
authSuccess(token) {
this.local.set('id_token', token);
this.user = this.jwtHelper.decodeToken(token).username;
let params:URLSearchParams = new URLSearchParams();
params.set('username', this.user);
this.authHttp.request('http://localhost:8000/api/user/', {
search: params
})
.map(res => res.text())
.subscribe(
data => this.local.set('user_info', JSON.stringify(JSON.parse(data)[0])),
err => console.log(err)
);
}只是我们的API似乎还不支持这样的功能。它的实现方式和我们之前的AutoComplete是一样的,也是搜索用户名:
def list(self, request):
search_param = self.request.query_params.get('username', None)
if search_param is not None:
queryset = User.objects.filter(username__contains=search_param)
serializer = UserSerializer(queryset, many=True)
return Response(serializer.data)然后再显示这些数据:
<div *ngIf="auth.authenticated()">
<div padding>
<h1>Welcome, {{ user }}</h1>
<h2 *ngIf="user_info">Last login {{user_info.last_login}}</h2>
<button block (click)="logout()">Logout</button>
</div>
</div>不过由于我们Django自带的用户管理模块只有这点信息,我们也就只能显示这些信息了。下一步,我们就可以实现在我们的APP里去创建博客。
在我们开始在APP端实现这个功能之前,我们先要实现一个高级点的用户授权管理——即只有用户登录或者用户的请求中带有Token的时候,我们才能创建博客。于是在这里我们所要做的就是实现一个IsAuthenticatedOrReadOnly,来判断用户是否有权限,如果没有的话,那么只让用户看到博客的内容。代码如下所示:
SAFE_METHODS = ['GET', 'HEAD', 'OPTIONS']
class IsAuthenticatedOrReadOnly(BasePermission):
"""
The request is authenticated as a user, or is a read-only request.
"""
def has_permission(self, request, view):
if (request.method in SAFE_METHODS or
request.user and
request.user.is_authenticated()):
return True
return False
class BlogpsotSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = Blogpost
fields = ('title', 'author', 'body', 'slug', 'id')
# ViewSets define the view behavior.
class BlogpostSet(viewsets.ModelViewSet):
permission_classes = (permissions.IsAuthenticatedOrReadOnly,)
queryset = Blogpost.objects.all()
serializer_class = BlogpsotSerializer接着,我们可以创建一个Modal来做这个工作。对于我们的博客表单来说,和登录没有太大的区别。
<form #blogpostForm="ngForm" (ngSubmit)="create(blogpostForm.value)">
<ion-item>
<ion-label>标题</ion-label>
<ion-input type="text" ngControl="title"></ion-input>
</ion-item>
<ion-item>
<ion-label>作者</ion-label>
<ion-input type="text" ngControl="author"></ion-input>
</ion-item>
<ion-item>
<ion-label>URL</ion-label>
<ion-input type="text" ngControl="slug"></ion-input>
</ion-item>
<ion-item>
<ion-label>内容</ion-label>
<ion-textarea type="text" ngControl="body"></ion-textarea>
</ion-item>
<div padding>
<button block type="submit">创建</button>
</div>
</form>稍有不同的是在我们的标题栏里会有一个关闭按钮。
<ion-toolbar>
<ion-title>
创建博客
</ion-title>
<ion-buttons start>
<button (click)="close()">
<span primary showWhen="ios">取消</span>
<ion-icon name="md-close" showWhen="android,windows"></ion-icon>
</button>
</ion-buttons>
</ion-toolbar>对于我们的实现代码来说,也是类似的,除了我们在发表成功的时候做的事情不一样——关闭这个Modal。
close() {
this.viewCtrl.dismiss();
}
create(value) {
this.contentHeader = new Headers({"Content-Type": "application/json"});
this.authHttp.post('http://127.0.0.1:8000/api/blogpost/', JSON.stringify(value), {headers: this.contentHeader})
.map(res => res.json())
.subscribe(
data => this.postSuccess(data),
err => console.log(err)
);
}
postSuccess(data) {
this.close()
}同时,我们需要在我们的首页里添加这样的一个入口。
<button fab fab-bottom fab-right (click)="createBlog()" calm>
<ion-icon name="add"></ion-icon>
</button>以及它的处理逻辑:
createBlog() {
let modal = Modal.create(CreateBlogModal);
this.nav.present(modal)
}为了实现在移动设备上的访问,这里就以riot.js为例做一个简单的Demo。不过,首先我们需要在后台判断用户是来自于某种设备,再对其进行特殊的处理。
幸运的是我们又找到了一个库名为django_mobile,可以根据用户的User-Agent来区别设备,并为其分配一个移动设备专用的模板。因此,我们需要安装这个库:
pip install django_mobile并将'django_mobile.middleware.MobileDetectionMiddleware'和'django_mobile.middleware.SetFlavourMiddleware'添加MIDDLEWARE_CLASSES中:
MIDDLEWARE_CLASSES = (
'django.contrib.sessions.middleware.SessionMiddleware',
'corsheaders.middleware.CorsMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.auth.middleware.SessionAuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'django.contrib.flatpages.middleware.FlatpageFallbackMiddleware',
'django_mobile.middleware.MobileDetectionMiddleware',
'django_mobile.middleware.SetFlavourMiddleware'
)修改Template配置,添加对应的loader和context_processor,如下所示的内容即是修改完后的结果:
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [
'templates/'
],
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
'django_mobile.context_processors.flavour'
],
},
},
]
# dirty fixed for https://github.com/gregmuellegger/django-mobile/issues/72
TEMPLATE_LOADERS = TEMPLATES[0]['OPTIONS']['loaders']我们在LOADERS中添加了'django_mobile.loader.Loader',在context_processors中添加了django_mobile.context_processors.flavour。
然后在template目录中创建template/mobile/index.html文件,即可。
为了方便我们讲述模块化,也不改变系统原有架构,我决定挖个大坑使用Riot.js来展示这一部分的内容。
Riot拥有创建现代客户端应用的所有必需的成分:
等等。
接着让我们引入riot.js这个库,顺便也引入rxjs吧:
<script src="{% static 'js/mobile/riot+compiler.min.js' %}"></script>
<script src="{% static 'js/mobile/rx.core.min.js' %}"></script>由于我们所要做的服务比较简单,并且我们也更愿意使用Promise来加载API服务,因此我们引入了这个库来加速我们的开发。下面是我们用于获取博客API的代码:
var responseStream = function (blogId) {
var url = '/api/blogpost/?format=json';
if(blogId) {
url = '/api/blogpost/' + blogId + '?format=json';
}
return Rx.Observable.create(function (observer) {
jQuery.getJSON(url)
.done(function (response) {
observer.onNext(response);
})
.fail(function (jqXHR, status, error) {
observer.onError(error);
})
.always(function () {
observer.onCompleted();
});
});
};当我们想访问特定博客的时候,我们就传博客ID进去——这时会使用'/api/blogpost/' + blogId + '?format=json'作为URL。接着我们创建了自己定制的事件流——使用jQuery去获取API:
在使用的时候,我们只需要调用其subscribe方法即可:
responseStream().subscribe(function (response) {
})现在,我们可以修改原生的博客模板,将其中的container内容变为:
<div class="container" id="container">
<blog></blog>
</div>接着,我们可以创建一个blog.tag文件,添加加载这个文件:`
<script src="{% static 'riot/blog.tag' %}" type="riot/tag"></script>为了调用这个tag的内容,我们需要在我们的main.js加上一句:
riot.mount("blog");随后我们可以在我们的tag文件中,来对blog的内容进行操作。
<blog class="row">
<div class="col-sm-4" each={ opts }>
<h2><a href="#/blogDetail/{id}" onclick={ parent.click }>{ title }</a></h2>
{ body }
{ posted } - By { author }
</div>
<script>
var self = this;
this.on('mount', function (id) {
responseStream().subscribe(function (response) {
self.opts = response;
self.update();
})
})
click(event)
{
this.unmount();
riot.route("blogDetail/" + event.item.id);
}
</script>
</blog>在Riot中,变量默认是以opts的方式传递起来的,因此我们也遵循这个方式。在模板方面,我们遍历每个博客取出其中的内容:
<div class="col-sm-4" each={ opts }>
<h2><a href="#/blogDetail/{id}" onclick={ parent.click }>{ title }</a></h2>
{ body }
{ posted } - By { author }
</div>而博客的数据需要依赖于我们监听mount事件才会去获取——即我们加载了这个tag。
this.on('mount', function (id) {
responseStream().subscribe(function (response) {
self.opts = response;
self.update();
})
})在这个页面中,还有一个单击事件onclick={ parent.click },即当我们点击某个博客的标题时执行的函数:
click(event)
{
this.unmount();
riot.route("blog/" + event.item.id);
}我们将卸载当前的tag,然后加载blogDetail的内容。
在我们加载之前,我们需要先配置好blogDetail。我们仍然使用正则表达式blogDetail/*来获取博客的id:
riot.route.base('#');
riot.route('blog/*', function(id) {
riot.mount("blogDetail", {id: id})
});
riot.route.start();然后将由相应的tag来执行:
<blogDetail class="row">
<div class="col-sm-4">
<h2>{ opts.title }</h2>
{ opts.body }
{ opts.posted } - By { opts.author }
</div>
<script>
var self = this;
this.on('mount', function (id) {
responseStream(this.opts.id).subscribe(function (response) {
self.opts = response;
self.update();
})
})
</script>
</blogDetail>同样的,我们也将去获取这篇博客的内容,然后显示。
在上面的例子里,我们少了一部分很重要的内容就是在页面间跳转,现在就让我们来创建navbar.tag吧。
首先,我们需要重新规则一下route,在系统初始化的时候我们将使用的路由是blog,在进入详情页的时候,我们用blog/*。
riot.route.base('#');
riot.route('blog/*', function (id) {
riot.mount("blogDetail", {id: id})
});
riot.route('blog', function () {
riot.mount("blog")
});
riot.route.start();
riot.route("blog");然后将我们的navbar标签放在blog和blogDetail中,如下所示:
<blogDetail class="row">
<navbar title="{ opts.title }"></navbar>
<div class="col-sm-4">
<h2>{ opts.title }</h2>
{ opts.body }
{ opts.posted } - By { opts.author }
</div>
</blogDetail>
当我们到了博客详情页,我们将把标题作为参数传给title。接着,我们在navbar中我们就可以创造一个breadcrumb导航了:
最后可以在我们的blogDetail标签中添加一个点击事件来跳转到首页:
clickTitle(event) { self.unmount(true); riot.route(“blog”); } ```
作为一个开源项目,我们在这方面做得并不是特别好——当然是有意如此的。不过,这里我们还是做一些简单的介绍。对于我们的项目来说,我们需要一些额外的配置,如我们的数据库中的DATABASES、DEFAULT_AUTHENTICATION_CLASSES、CORS_ORIGIN_ALLOW_ALL、SECRET_KEY应该在不同的环境中都有不同的配置。
我们可以一个创建local_settings.py,在里面放置一些关键的服务器相关的配置,如:
# SECURITY WARNING: keep the secret key used in production secret!
SECRET_KEY = 'hpi!zb8!(j%40)r55@+_5k*^9qcjf9sx0o_it*jlp3=x9^2ak@'
# SECURITY WARNING: don't run with debug turned on in production!
DEBUG = True
TEMPLATE_DEBUG = True
# Database
# https://docs.djangoproject.com/en/1.7/ref/settings/#databases
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': 'db.sqlite3',
}
}
REST_FRAMEWORK = {
'DEFAULT_PERMISSION_CLASSES': (
),
'DEFAULT_AUTHENTICATION_CLASSES': (
'rest_framework.authentication.SessionAuthentication',
'rest_framework.authentication.BasicAuthentication',
'rest_framework_jwt.authentication.JSONWebTokenAuthentication',
),
}
CORS_ORIGIN_ALLOW_ALL = True接着,我们只需要在我们的主settiings.py中引用即可。